1.Langchainとは
ChatGptやGeminiなどの生成AIはそのままだと「質問に答える」くらいしかできませんが、LangChainを使うと
・外部データを読み込む
・複数の処理を順番につなぐ
・目的に特化したAI
を作ることができます。
1.1.外部データを読み込むについて
生成AIは事前に学習していない社内資料やPDFファイルの中身を知りません。
LangChainを使うと、
・社内マニュアル(PDF・Wordなどのファイル全般)
・データベース
・ExcelやCSV
・Webページ
などを読み込ませて、その内容を元に回答させることができます。
1.2.複数の処理を順番につなぐ
よく使うChatgptのような生成AIは「1回考えて一回答える」だけです。
LangChainでは、
1.質問を整理する
2.必要な資料を探す
3.内容を要約する
4.結果を分かりやすく出力する
といった一連の流れ(ワークフロー)を作れます。
1.3 目的に特化したAI
汎用的な機能を持った生成AIを使用することが多いですが、
LangChainでは
・社内FAQだけ答えるAI
・契約書をチェックするAI
・業務手順を案内するAI
のように、役割を限定したAIを作れます。
2.実際にコードを作ってみた
本章では、特定のPDFを読み込ませてその情報を要約するAIを作ります。
※補足
実装を試してみたい人向け
vscodeでpythonの実行環境とLangChainの実行環境を整える必要があります。
その後、openAIのAPIキーを取得する必要があります。(実行するたびにお金がかかります。)
実験用PDFファイルがない方でも「政府統計の総合窓口」から取得できます。
今回は、都道府県/政令指定都市別の一人当たり居住スペースのデータを取得します。
ライブラリの読み込みと環境設定
from langchain.text_splitters import RecursiveCharacterTextSplitter
from pypdf import PdfReader
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain.chat_models import init_chat_model
import config
import os
PDFファイルの読み込み
textにPDFの文字列が入っています。
BASEDIR = os.path.dirname(os.path.abspath(__file__))
os.chdir(BASEDIR)
PDF_PATH = "liveArea.pdf"
if not os.path.exists(PDF_PATH):
print("PDFファイルが見つかりません。")
text = "".join(
(page.extract_text() or "")
for page in PdfReader(PDF_PATH).pages
)
テキスト分割
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
docs = [
Document(page_content=c)
for c in splitter.split_text(text)
]
chunk_size・・・AIが読み込みやすいように指定した文字ごとに文章を分割する
多いと回答がぼんやりする。少ないと回答が断片的な情報からになる
chunk_overlap・・・文章が途中で分断されても意味が通じるように隣接チャンク同士を重複させる。
多いとチャンクが増えすぎる。少ないと意味が通じなくなる
ベクトル化とデータバース作成
vectorstore = Chroma.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(
api_key=config.OPENAI_API_KEY,
model="text-embedding-3-small"
)
)
documents・・・pdfドキュメントが入っている
vectorstore・・・チャンクごとに分かれた文章とベクトル情報が入る
ChatModelの初期化
chat_model = init_chat_model(
"gpt-5-nano",
api_key=config.OPENAI_API_KEY
)
チャットボット関数
def chatbot(question: str):
retrieved_docs = vectorstore.similarity_search(
question,
k=3
)
context = "\n".join(
doc.page_content for doc in retrieved_docs
)
messages = [
{
"role": "system",
"content": "あなたはPDFの内容に基づいて質問に答えるアシスタントです。"
},
{
"role": "user",
"content": f"以下は質問に関連して抜粋されたドキュメントです:\n{context}"
},
{
"role": "user",
"content": f"質問:\n{question}"
},
]
response = chat_model.invoke(messages)
return response.content, retrieved_docs
・この関数内部で質問→検索→回答生成を行っている
・ 2行目のvectorstore.similarity_searchで質問文(question)とチャンクごとに分かれた文章を取得し、質問文とベクトル情報が類似しているもの上位3件取得する。
・context はretrieved_docsのメタデータを省いたもの。(意味が分からなければAIが文章を読めるように無駄な情報を省いたものだと理解すればOK)
・そして、messages にユーザーの質問とドキュメント情報をまとめて、response = chat_model.invoke(messages)の行でAIに回答を生成してもらっている
実行箇所
if __name__ == "__main__":
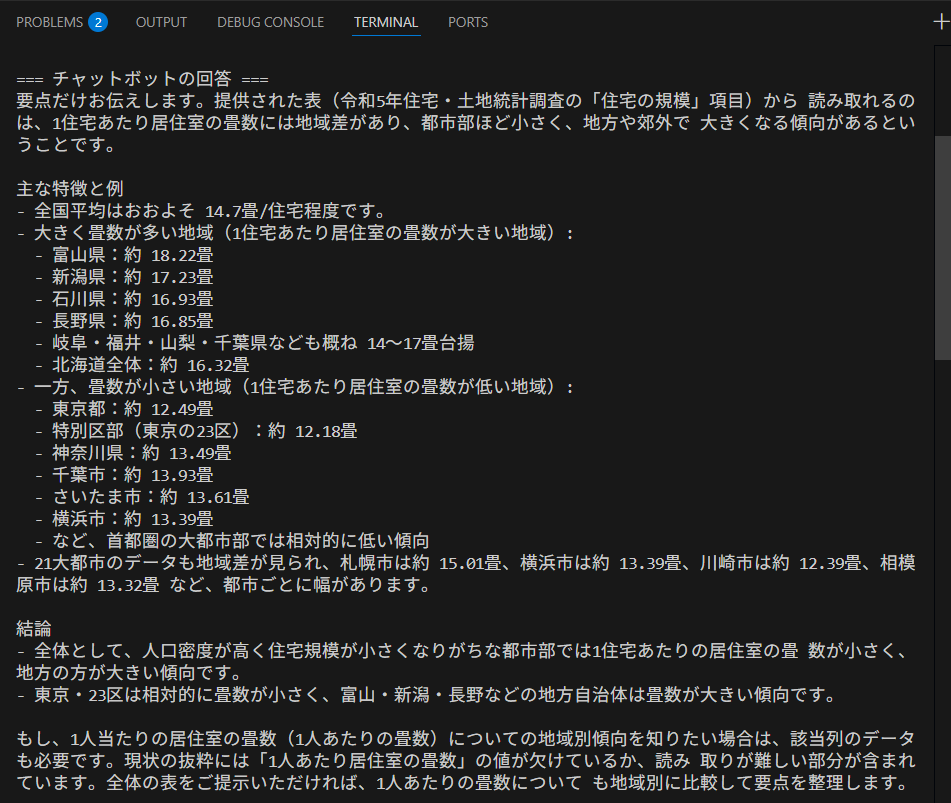
q = "1人あたりの住居室畳数の地域的な傾向を教えてください。"
answer, docs = chatbot(q)
print("\n=== チャットボットの回答 ===")
print(answer)
print("\n=== 参照されたドキュメント ===")
for i, doc in enumerate(docs, 1):
print(f"\n--- ドキュメント {i} ---")
print(doc.page_content)
・answer, docs = chatbot(q)でさきほどのチャットボット関数を呼出し。
・q = "1人あたりの住居室畳数の地域的な傾向を教えてください。"がユーザーの質問文。
以下に結果を載せます。
ちなみにですが、もちろんGUIを実装することもできます。
以下参考画像
 (←参考になった場合はハートマークを押して評価お願いします)
(←参考になった場合はハートマークを押して評価お願いします)