「オワコン」だったはずのナレッジグラフが、なぜ最前線に戻ってきたのか
なぜ今、ナレッジグラフ(KG)が再び注目されているのでしょうか。答えはシンプルで、KGが「求められ」「作れて」「効く」ための条件が、2023〜2026年にかけて一気に揃ったからです。具体的には、①ベクトルRAGの限界露呈(需要)、②LLMによる構築コストの破壊、③LazyGraphRAG等による運用コストの破壊、④推論モデルとの相乗(能力)という4つの技術ドライバーが、相次いで出揃いました。最初の1つが「なぜ求められるのか(需要側)」、続く2つが「なぜ作れて・安く回せるのか(供給/コスト側)」、最後の1つが「なぜ以前より効くのか(能力側)」に対応します。
ナレッジグラフという概念自体は新しいものではありません。セマンティックWebの理想として語られ、2012年のGoogle Knowledge Graphで一躍脚光を浴びた、いわば「枯れた技術」です。しかし、エンティティやリレーションを人手で設計・抽出する構築コストの高さがネックとなり、一部では「重い」「古い」「割に合わない」技術と見られていた時期もありました。RAGがベクトル検索一辺倒で語られがちだったのも、その裏返しと言えるでしょう。
その前提が、今や根本から覆りつつあります。この記事は「KGが流行っています」という紹介記事ではありません。なぜ一度は脇に追いやられた技術が、このタイミングで再点火したのか――その因果を、LLM/RAGの基礎を持つ中級エンジニアの視点で解きほぐしていきます。
この記事は、おおむね次の順で進みます。
- 前提整理:ナレッジグラフとは何か、ベクトルRAGとGraphRAGはどう違うのか
- 4つのドライバー:「なぜ今か」を一つずつ因果で掘り下げる
- 動かぬ証拠:クラウド各社の動きから「今が転換点である」ことを確認する
- 冷静な評価:手放しの礼賛で終わらせず、日本語データの壁や「使うべきでない場面」まで見る
とりわけ、競合記事があまり触れてこなかった「ローカルLLM×ナレッジグラフ」という構成や、日本語データでのエンティティ抽出の難しさといった、実務でつまずきやすい論点にも踏み込みます。枯れたはずの技術が最前線に戻る瞬間に立ち会う、その面白さを共有できればと思います。
そもそもナレッジグラフとは?──ベクトルRAGとGraphRAGの違いを30秒で整理する
結論から言うと、ここで本当に比べるべきは「ナレッジグラフ(KG) vs RAG」ではありません。 まず用語を整理しましょう。RAG(検索拡張生成)は「外部知識を検索してLLMに渡す」枠組みの総称で、その実装は大きく2系統に分かれます。文書をベクトル化して意味の近さで引くベクトルRAGと、知識をグラフ構造で持って関係を辿るGraphRAGです。普段わたしたちが単に「RAG」と呼ぶのはたいていベクトルRAGのことですが、GraphRAGも同じRAGの一種です。そして**ナレッジグラフ(KG)は、そのGraphRAGが土台にする「知識の表現方式」**にあたります。
したがって意味のある対比は、同じRAGという枠組みの中での**「知識の持ち方」の違い**――ベクトル空間上の近さで持つベクトルRAGか、明示的な関係のネットワーク(=KG)で持つGraphRAGか――です。前者は単発の事実検索に強く、後者は関係を辿る推論に強い、というのが30秒での答えになります。本記事の主役は後者の土台となるKGで、これがなぜ今あらためて注目されているのかを掘り下げていきます。まずはそのKG自体から見ていきましょう。
ナレッジグラフ=エンティティを関係でつないだ知識表現
ナレッジグラフの基本単位はトリプルです。(エンティティ)-[関係]->(エンティティ) という3つ組で1つの事実を表します。
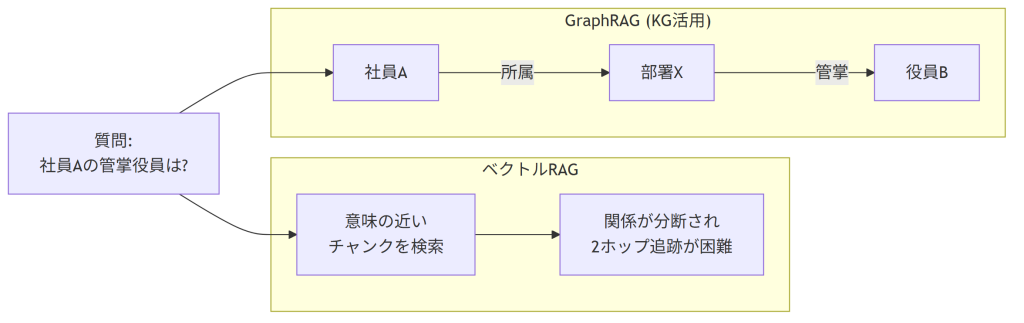
(東京) -[首都]-> (日本)(社員A) -[所属]-> (部署X) -[管掌]-> (役員B)
2つ目の例のように、トリプルをつなげていくと「社員Aの管掌役員は誰か」という問いに、関係を2つ辿る(2ホップ)だけで到達できます。エンティティがノード、関係がエッジにあたるグラフ構造です。
ベクトル検索が苦手なところを、グラフ(KG)は構造で解く
従来のベクトルRAGは、クエリと意味的に近いチャンクを引いてくる仕組みです。「Xとは何か」のような単発の事実検索は得意ですが、次の2つは原理的に苦手です。
- マルチホップ推論: 「社員Aの管掌役員」のように、複数の事実を連鎖させて辿る問い。チャンクが別々の文書に散っていると、意味的な近さだけでは関係をつなげられません。
- 俯瞰的な要約: 「データ全体で最も重要なテーマは何か」のような、個別チャンクではなく全体像を問う質問。
KGは関係を明示的なエッジとして持つため、こうした「辿る」「俯瞰する」処理を構造そのもので解けます。このKGを検索基盤に据えたRAGが、すなわちGraphRAGです。
よくある誤解:「KG=GraphRAG」ではない
念のため、よくある混同にも触れておきます。KGはGraphRAGのために生まれたわけではありません。 ナレッジグラフは、RAGという言葉が広まるはるか以前――セマンティックWebや2012年のGoogle Knowledge Graphの時代――から存在する、独立した知識表現の方式です。GraphRAGは、その「枯れた土台」をLLM時代の検索基盤として再利用する新しい使い方にすぎません。古い土台(KG)の上に新しい使い方(GraphRAG)が乗った――この時間軸の捉え方が、後半で見る「なぜ”今”なのか」の伏線になります。
ドライバー①──ベクトルRAGの限界露呈で「需要」が生まれた
4つのドライバーの最初は、供給側ではなく需要側の話です。そもそも、なぜKGがあらためて「求められる」ようになったのか。きっかけは皮肉にも、対抗馬であるベクトルRAGの大普及でした。
2023年から2024年にかけて、RAGといえばベクトル検索、というスタイルが一気に定着しました。とりあえず文書を埋め込み、近いチャンクを引いてLLMに渡す――この手軽さで多くのチームがRAGを実運用に乗せます。ところが本番データで使い込むほど、同じ壁に大規模にぶつかり始めました。前掲のとおり、これは実装が下手だからではなく、「意味の近さでチャンクを引く」という方式そのものの原理的な天井です。
- マルチホップが解けない:「この部品の不具合は、どの製品系列の、どの顧客に波及するか」のように、複数の事実を関係でつないで初めて答えが出る問い。チャンクが別文書に散ると、近さだけでは関係をつなげられません。
- 俯瞰的な問いに答えられない:「全社の文書を通して、最大のリスクテーマは何か」のような全体像を問う質問。個別チャンクの寄せ集めでは構造的に拾えません。実は、MicrosoftがGraphRAGを提案した動機そのものが、この「データセット全体にまたがる問い」でした。
- 根拠をたどれない/ハルシネーション:なぜその答えになったのかを関係で説明できず、確率的に近いチャンクを引くだけでは事実を保証できない。規制領域(法務・医療・金融)では使いづらい弱点です。
重要なのは、これらの限界自体は新しくない、という点です。新しいのは、RAGが主流になって初めて、この天井に「皆が同時に」ぶつかったこと。痛みが広く共有されて初めて、「ならば関係を明示的に持つ構造=ナレッジグラフへ」という需要が顕在化しました。つまりベクトルRAGの普及こそが、その限界を露呈させ、KG再評価の地ならしをした――これが第一のドライバーです。
そして需要が生まれても、肝心の「作れる・安く回せる・賢く使える」が伴わなければ流行りません。続く3つのドライバーが、まさにそこを埋めました。
ドライバー②──LLMが「構築コスト」を破壊した
需要が生まれても、長らくKGには「そもそも作るのが高すぎる」という供給側の壁がありました。これまで一部の大企業や検索エンジン以外に広く普及してこなかった最大の理由が、この「構築コスト」です。
従来、ナレッジグラフを作るには、ドメインに精通した専門家がスキーマ(どんなエンティティと関係を扱うか)を設計し、文書の中から人手でエンティティを抽出し、それらの関係を一つひとつ定義していく必要がありました。これは典型的に専門家の「人月」を要する作業であり、多くのプロジェクトにとって投資対効果が見合わないものでした。グラフの価値は理解されていても、入口でつまずいていたわけです。
LLMはこの構図を根底から変えました。文書から「誰が・何を・どう関係しているか」を読み取る作業こそ、まさに大規模言語モデルが得意とするタスクだからです。これにより、これまで人手に依存していたエンティティ抽出・関係定義が自動化され、参入障壁が劇的に下がりました。これが、ナレッジグラフ再点火の第二のドライバーです。
抽出パイプラインの自動化
この変化を具体的に示すのが、Neo4jが公式に提供する「LLM Knowledge Graph Builder」です。これは非構造データ(社内文書・会議のトランスクリプト・Web記事・Wikipediaの記事など)を取り込み、グラフDBへ格納するまでを一気通貫で自動化するツールです。処理の流れはおおむね次のようになっています。

対応するLLMの選択肢も幅広く、GPT-4o系・Gemini・Llama 3.x・Claude 3.5 Sonnet・Qwen、さらにローカル実行向けのOllama経由のモデルまでサポートされています。クラウドのフラッグシップモデルからローカルモデルまで選べる点は、次の項で触れるローカル構成とも密接に関わってきます。
Neo4jはこのアプローチについて、「従来は数千行のPythonコードを要した処理が、約50行のCypher(同社のグラフクエリ言語)に置き換えられる」と主張しています。もっとも、これはツールを提供するベンダー自身の主張である点は割り引いて受け止める必要があります。実際の削減幅はユースケースやデータの性質に大きく依存するため、数字そのものより「桁が変わるレベルで手間が減りうる」という方向性として捉えるのが妥当でしょう。
しかも「ローカル」でも作れる時代になった
構築コスト破壊の象徴が、ローカルLLMでの構築です。「ローカルLLMでナレッジグラフは作れるのか?」――答えは、すでに現実的に動きます。クラウドのフラッグシップモデルに頼らずとも、手元のマシン1台でKGの構築・検索が完結する構成が、具体的なレシピとして出回っています。
具体例を2つ挙げます。
- Neo4j × Ollama ×
text2cypher(出典: GreenFlux):Docker版のNeo4jとOllamaを組み合わせ、text2cypher(Gemma 2 9Bをファインチューンした自然言語→Cypher変換モデル)を使う構成。自然言語の質問をローカルモデルがCypherクエリに変換し、ローカルのNeo4jへ問い合わせる――これが自分のマシン上で完結します。 - CPUだけで完結するパイプライン(出典: Neo4j Medium):Neo4jをベクトルストアとして使い、HuggingFaceの埋め込みモデル(
all-MiniLM-L6-v2)、LangChain、Ollama/Mistralを組み合わせた構成。”No cloud APIs, no GPUs”(クラウドAPIなし・GPUなし)を掲げ、GPUを持たない手元のラップトップでも回せます。
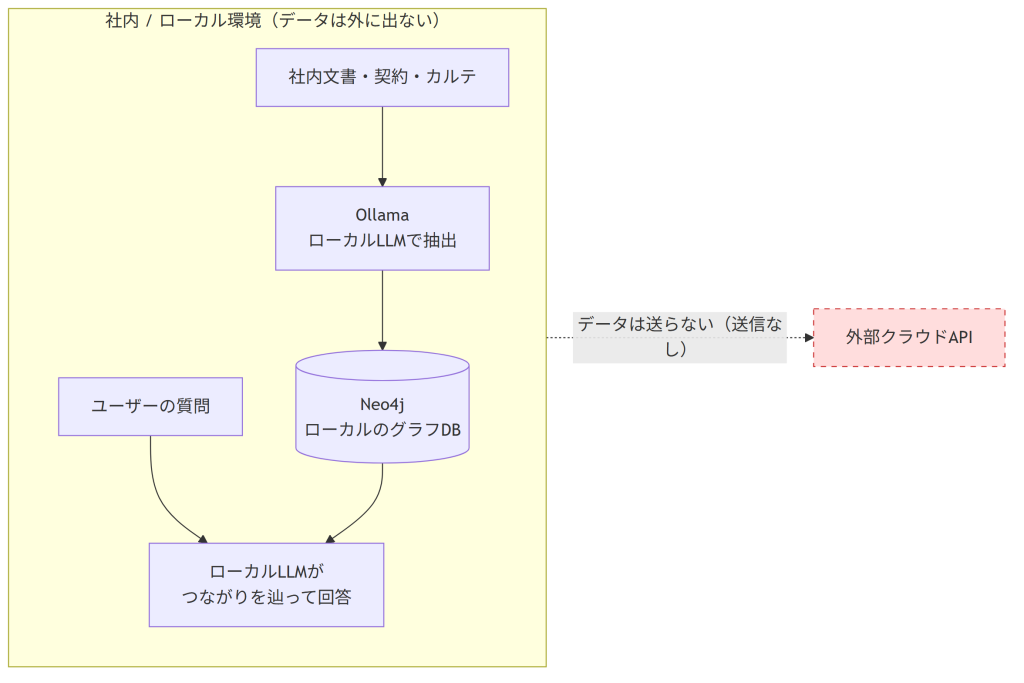
ここで一点、誤解を避けておきます。「ローカルで完結=データを外に出さずに済む」という閉域メリットは確かにありますが、これはKG固有の利点ではありません。ローカル埋め込み+ローカルのベクトルDBを使えば、ベクトルRAGでも同じく閉域で組めるからです。だからローカル実行そのものを「KGが熱い理由」に数えるのは正確ではありません。ここで本当に効いているのは、あくまで構築コストの破壊――かつて専門家の人月を要したKG構築が、いまや特別なインフラもクラウド課金もなしに、中級エンジニアが週末のラップトップで試せるところまで降りてきた、という事実です。「熱さ」が一部の大企業だけのものではなくなった、という点こそが重要なのです。
もっとも、ローカル構成は誇張禁物です。クラウドのマネージドサービスのような滑らかさは期待できず、実際には次のような手間がつきまといます。
- 出力パースの手間:ローカルモデルが回答をmarkdownのコードブロックで勝手に包んでくるなど、後処理が必要になりがち
- バージョン不整合:LangChainと依存ライブラリのバージョンずれに悩まされる
- 接続設定そのものが鬼門:各コンポーネントをつなぐ設定が「最も難しい部分(The Hardest Part)」と評されることもある
ただし「タダ」ではない──そして「運用コスト」へ
ここで一点、釘を刺しておく必要があります。LLMによる抽出は決して「タダ」ではありません。人手の専門作業がモデルへの問い合わせに置き換わった結果、今度はAPI課金という別種のコストが発生します。
実際、Microsoftの文書をベースにした報告では、グラフ抽出(graph extraction)の工程がインデックス構築の総コストのうち約75%を占めると報告されています。抽出という最も価値の高い工程が、同時に最もコストのかかる工程でもあるわけです。
つまり今回の変化の本質は、「専門家の人月コストが消えた」ことではなく、「人月コストがAPI課金(indexing)コストへと姿を変えた」ことだと言えます。そして、この新しい運用コストこそが、長らくGraphRAG普及の最後の壁でした。――が、その壁もいま崩れつつあります。それが第三のドライバーです。
ドライバー③──LazyGraphRAG等が「運用コスト」を破壊した
第二のドライバーで構築の入口は安くなりましたが、引き換えにindexing(インデックス構築)の運用コストという新たな壁が生まれました。LLMで大量の文書からエンティティ・関係を抽出する処理は重く、一部の報告ではGraphRAGのindexingが単純なvector RAGの100〜1000倍に達するとも言われます(条件依存の伝聞であり、ワークロードによって大きく変動します)。「精度は上がるが、高すぎて常用できない」――これがGraphRAG普及を阻む最後の関門でした。
この関門を直接崩しにきたのが、2024〜2025年に相次いで登場した低コスト化技術です。代表格がLazyGraphRAGで、事前に全グラフを構築せず、クエリが来たときに必要な範囲だけを遅延評価(lazy)します。Microsoftは、LazyGraphRAGを「フルなGraphRAGのごく一部(一説に約0.1%)のインデックスコストで、同等以上の回答品質を出せる」と位置づけています(条件依存の報告値)。同じ方向で、抽出範囲を絞るKET-RAGやTERAGといった手法も登場しています。
効果は研究にとどまりません。前述のとおり、MicrosoftはこのLazyGraphRAGを科学研究向けエージェント基盤「Microsoft Discovery」の中核に据えています。「高コストだから実験止まり」だったGraphRAGが、「実運用に乗せられるコスト」へと降りてきた――この運用コストの破壊が、第三のドライバーです。
念のため補足すると、コスト最適化はまさに研究が今まさに解いている途上のテーマで、万能の特効薬が確立したわけではありません。それでも「高すぎて、試す前に諦める」段階は明確に終わりつつある、というのが”今”の状況です。
ドライバー④──推論モデル×GraphRAGの相乗
第四の波は、最も新しく、そして最も本質的かもしれません。2025年初頭に登場したDeepSeek R1やOpenAI o1に代表される「推論モデル(reasoning model)」の台頭です。これがナレッジグラフ再評価の第四の再点火要因になっています。
なぜ推論モデルがKGと結びつくのか。両者は欠点と長所がきれいに裏返しの関係にあるからです。推論モデルは「考える」ことに長けています。問いを分解し、中間ステップを積み上げ、結論へ至る。しかし、その推論が立脚する「事実」を自分自身では保証できません。つまりハルシネーションします。一方、ナレッジグラフは「事実」をエンティティとリレーションの構造として明示的に保持しますが、それ自体は何も考えません。推論モデルが「思考エンジン」、KGが「事実の基盤」として噛み合うことで、複数の事実をたどるマルチホップな問いに、ハルシネーションを抑えて答える道筋が見えてきました。
この変化を「変曲点」と位置づける見方があります。RAGFlowを開発するInfiniFlowは、「DeepSeek R1の衝撃がLLM推論能力の予測を半年以上前倒しした」とし、2025年春を「推論強化LLMが人手によるオーケストレーションを最小化する変曲点」と評しています(確度MEDIUM)。
設計思想の転換も具体的です。従来のRAGは「query → retrieval → response」という単純な一方向の検索でした。これが「分解 → 検索 → 統合」を繰り返す反復サイクルへと変わりつつあります。さらに注目すべきは、その分解が汎用的なものではなく、「ナレッジグラフの構造に沿ったサブ問題分解(knowledge-aware decomposition)」へ向かっている点です。記号的(symbolic)なKGと、ニューラルな(neural)LLMを密に結合させる——これが現在のトレンドだと同社は指摘しています。
研究レベルでは、すでに具体的な成果も報告されています。MarkTechPostが取り上げたGraph-R1は、強化学習(GRPO)とエージェント的な多ターン推論を組み合わせ、「think → retrieve → rethink → generate」というループを回すアプローチです(確度MEDIUM)。報告されているAvg F1スコアは次のとおりです。
- GraphRAG:24.87
- HyperGraphRAG:29.40
- Search-R1:46.19
- Graph-R1:57.82
なお、この57.82はベースモデルにQwen2.5-7Bを用いた際の報告値であり、スコアの比較はベンチマークの条件(使用モデル・データセット・評価指標)に依存する点に留意が必要です。従来のKGPやLightRAGがマルチホップで2〜3ホップ止まりだった制約を、適応的なグラフ探索によって突破したと位置づけられています。
ここで一点、冷静に補足しておきます。これらの数値はあくまで研究で「報告されている」もので、ベンチマーク条件にも依存します。推論モデル×GraphRAGの領域は研究段階の話題が多く、実プロダクトでの一般化はこれからです。とはいえ、「考えるLLM」と「事実を持つKG」を結ぶという方向性そのものは、ここまでの3つのドライバー(需要の顕在化、構築コストと運用コストの破壊)と地続きであり、ナレッジグラフが「今熱い」第四の理由として説得力を持つものだと言えるでしょう。
実務の中級エンジニアにとって、この第四の波は「今すぐ本番システムに推論モデル×GraphRAGを採用すべき」という話ではまだありません。研究段階で一般化もこれからだからです。ただし、推論モデルにGraphRAGを組み合わせた小さなPoCを一度回しておけば、「マルチホップな問いをどう分解・検索・統合させるか」という設計の引き出しを先取りできます。来たるべき実用化に備えて、いま手元で感触をつかんでおく価値は十分にあるでしょう。
「今が転換点」の動かぬ証拠──クラウド各社が標準機能にした
前のセクションまでで、ベクトルRAGの限界露呈・構築コストの破壊・運用コストの破壊・推論モデルの相乗という4つのドライバーが揃ったことを見てきました。では、それらが「揃った」ことを示す最も客観的な証拠は何でしょうか。筆者は、クラウド各社がGraphRAG/ナレッジグラフを実験段階から「標準機能」へと昇格させた事実だと考えています。ベンダーが製品として組み込んだということは、技術リスクとコストが実用ラインを越えたという経営判断にほかなりません。
GraphRAGの起源はMicrosoft Research
そもそもGraphRAGは、Microsoft Researchの「Project GraphRAG」が起源です。これは、ソーステキストからのエンティティ・リレーション抽出、グラフのネットワーク分析(コミュニティ検出)、そしてLLMによるコミュニティ要約を、エンドツーエンドのパイプラインとして統合した手法でした。従来のベクトル検索だけでは拾えない「データセット全体にまたがる問い」に答えられる点が、最大の特徴です。
公式のGraphRAG実装では、ベクトル埋め込みを既定でLanceDBに保存しつつ、大規模デプロイではAzure AI Searchへ保存する構成が選べます。エンティティを起点に周辺を探索するlocal searchでも、シードエンティティの特定にAzure AI Searchなどのベクトルストアを利用します。グラフとベクトルが排他ではなく、組み合わせて使われている点に注目してください。
Azureプロダクトへの組み込みが進む
研究にとどまらず、Azure上の製品への組み込みが進んでいます。2025年、Build 2025前後には、軽量版のLazyGraphRAGを中核として、Azure上に構築された科学研究向けエージェント基盤「Microsoft Discovery」への統合が進みました(2025年6月にpublic preview)。また、Azure Cosmos DB(Gremlin API)を用いてAI駆動のナレッジグラフを構築する「CosmosAIGraph」が、Microsoft Learnでリファレンス実装として案内されています。GraphRAGを発祥させたMicrosoftが、自社のクラウド資産に着実に落とし込んでいる構図です。
AWSもGAで追随
傍証として、AWSの動きも併記しておきます。Amazon Bedrock Knowledge BasesのGraphRAGは、2025年3月7日にGA(一般提供)となりました。Amazon Neptune Analyticsと連携し、グラフの自動生成と、ベクトル類似検索+グラフ走査(graph traversal)のハイブリッド検索を提供します。GraphRAG発祥のMicrosoftがAzureで標準化を進め、AWSもGAで追随した──クラウド各社が足並みを揃えたという事実そのものが、転換点の何よりの証拠です。
4つのドライバーをAzureで実装するなら
Azureを主戦場にしている読者であれば、これら4つのドライバーを自分のスタックに引きつけて考えられます。
- ①ベクトルRAGの限界 → すでにAzure AI Searchでベクトル検索を運用し、マルチホップや俯瞰的な問いで頭打ちを感じている読者自身の課題そのもの
- ②構築コストの破壊 → 抽出を担うLLMをAzure OpenAI Service(またはAzure AI Foundry)で動かし、グラフストアにAzure Cosmos DB(Gremlin API、参考実装がCosmosAIGraph)、ベクトル側にAzure AI Searchを据える構成にマッピングできる
- ③運用コストの破壊 → LazyGraphRAGを中核に採用したMicrosoft Discoveryの方向性どおり、Azure側でもコスト最適化済みのGraphRAGに寄せていける
- ④推論モデルとの相乗 → Azure OpenAIのo系など推論対応モデルを、上記のグラフ/ベクトル基盤と組み合わせて取り込める
なお、データを外に出せない閉域要件には、Azure OpenAIのVNet統合・プライベートエンドポイントや、より厳格ならAzure Localといった選択肢が用意されています(これはKGに限らずベクトルRAGでも同様に効く、実装上の安心材料です)。いずれも現状の機能範囲で組める構成であり、誇張なく「Azureだけで4ドライバーを一通り試せる」段階に来ていると言えます。
精度の報告値
精度面でも、ナレッジグラフ併用の効果が報告されています。ある検証ではナレッジグラフによって回答精度が最大3倍(54.2% vs 16.7%)になったと報告されており、別の比較ではベクトル検索のみと比べてcomprehensiveness(網羅性)が72〜83%の勝率だったとも報告されています。いずれも条件依存の伝聞値であり鵜呑みは禁物ですが、傾向としては一貫しています。
採用タイムライン
4つのドライバーと各社採用の流れを時系列で整理すると、次のようになります。
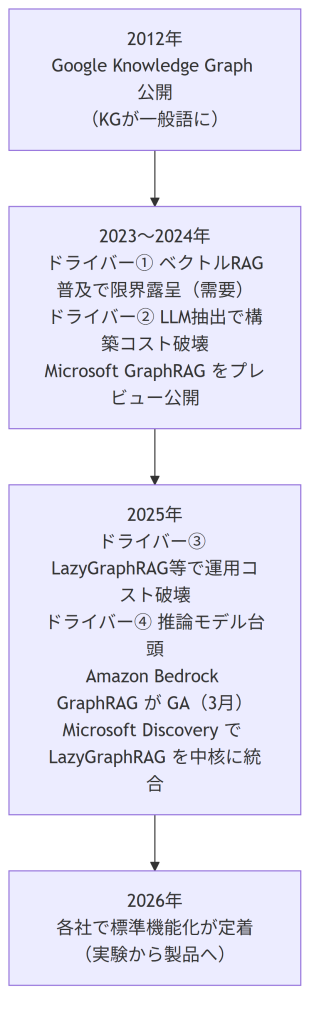
2012年のGoogle Knowledge Graphで「ナレッジグラフ」という言葉が広まってから十余年、ベクトルRAGの限界露呈から構築・運用コストの破壊、推論モデルの相乗まで、4つのドライバーが2023〜2026年に出揃い、それを追うようにクラウド各社が製品化に踏み切りました。技術が「使える」フェーズに入ったことを、市場の動きが裏づけています。
冷静に見る──「使うべきでないとき」と日本語の壁
ここまで「今が熱い」理由を述べてきましたが、ナレッジグラフ(KG)は銀の弾丸ではありません。導入判断を誤らないために、ここでは残る弱点と適用範囲を冷静に整理します。
精度の落とし穴は「言語依存」
まず注意したいのが抽出精度です。エンティティ抽出のF1スコアは英語で85〜92%と報告される一方、低リソース言語では50〜70%まで落ちるとの報告もあります。日本語データを扱う場合、固有名詞の区切りや表記ゆれ(「株式会社○○」と「○○」、全角・半角の混在など)の吸収が課題になりがちで、英語のベンチマーク値をそのまま期待すると痛い目を見ます。正規化・名寄せの前処理をどこまで作り込むかが、実用品質を分ける勘所です。
公平に見る──「過渡的技術」論への応答
「KGは基盤モデルの進化で役割が薄れる過渡的技術にすぎない」とする逆張りの論者もいます。モデルの長コンテキスト化や推論能力の向上を考えれば、傾聴に値する指摘です。ただし、事実の保証・出典の追跡・説明可能性が要件となる領域では、確率的に振る舞うモデルとは別に、明示的な事実の構造を持つKGの価値は当面続くと考えられます。両者は対立ではなく補完の関係にあります。
実務の判断軸
最終的には、自分のユースケースがどちらに属するかで判断します。ポイントは「機密だから」「ローカルだから」ではなく(それはベクトルRAGでも同じです)、問いが関係や全体像を必要とするかの一点です。
- 従来のvector RAGで十分なケース
- 単純なFAQへの応答
- 1ホップ(単一文書・単一事実)で答えが出る
- 文書内に答えが明示的に書かれている
- GraphRAG+KGを検討すべきケース
- 複数の事実をまたぐマルチホップな問い
- 関係性そのものが問われる(「AとBはどうつながっているか」)
- 回答の根拠・説明可能性が必須(法務・医療・コンプライアンス)
迷ったときは、次のフローで切り分けてみてください。
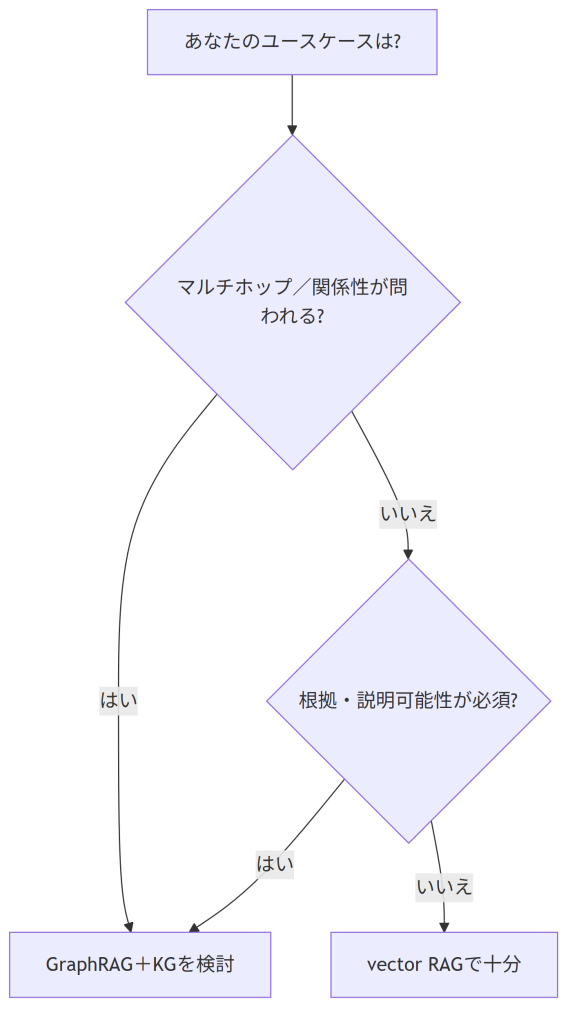
「今が熱い」のは事実です。しかしその熱は、すべての課題に向けられたものではありません。マルチホップ・関係性・説明可能性──この3つのいずれかが効くときにこそ、KGは投資に見合う技術になります。
まとめ──「枯れた技術」が最前線に戻った4つの理由
ナレッジグラフが2025-2026年に再び熱を帯びているのは、流行り廃りの偶然ではありません。長年KGの普及を阻んでいた壁が、4つの技術ドライバーによって相次いで崩れた結果です。
- ① ベクトルRAGの限界が露呈し「需要」が生まれた:RAGの大普及でマルチホップ・俯瞰・説明可能性の壁に皆が同時に直面し、「関係を明示的に持つ構造」への需要が顕在化しました。
- ② LLMが構築コストを破壊した:人手のスキーマ設計・エンティティ抽出が自動化され、ローカルのラップトップでも作れるほど参入のハードルが桁違いに下がりました。
- ③ LazyGraphRAG等が運用コストを破壊した:GraphRAG最大の弱点だったindexingコストが、遅延評価などの新技術で実運用ラインまで下がりました。
- ④ 推論モデルがKGと噛み合った:「考えるが事実を持たない」LLMと「事実を持つが考えない」KGの結合が、マルチホップな問いをハルシネーションなく解く道を開きました。
そしてこの4つが揃ったことは、Microsoftが発祥のGraphRAGをAzureに組み込み、AWSがGAで追随したというクラウド各社の足並みに、何より客観的に表れています。
一方で、コストは「消えた」のではなく「運用コストへ移動し、それも下がりつつある」段階だということ、抽出精度は言語依存で日本語には固有の難しさがあること、そして万能ではなくマルチホップ・関係性・説明可能性のいずれかが効く場面でこそ価値を発揮することも、忘れてはいけません。
「ナレッジグラフは古い」という印象を持っていた方こそ、いまの土台の変化を一度自分の手で確かめてみる価値があります。ローカル構成なら、週末のラップトップ1台から始められます。
参考リンク
- LLM Knowledge Graph Builder—First release of 2025(Neo4j 公式ブログ)
- Building a Knowledge Graph Locally with Neo4j & Ollama(GreenFlux)
- Building GraphRAG Locally(Neo4j Developer Blog / Medium)
- Graph-R1: An Agentic GraphRAG Framework with Reinforcement Learning(MarkTechPost)
- Reasoning for RAG: A 2025 Perspective(InfiniFlow / RAGFlow)
- Amazon Bedrock Knowledge Bases GraphRAG が一般提供開始(AWS 公式)
- Project GraphRAG(Microsoft Research)
- GraphRAG 公式ドキュメント(Microsoft)
- AI Knowledge Graphs – Azure Cosmos DB(Microsoft Learn)
 (←参考になった場合はハートマークを押して評価お願いします)
(←参考になった場合はハートマークを押して評価お願いします)