この記事は更新から24ヶ月以上経過しているため、最新の情報を別途確認することを推奨いたします。
はじめに
本記事は、2018年4月に記載したApp Service におけるスケールルールを更新した内容となります。
App Service には、設定したメトリクスや時間によって、インスタンスを拡張し、性能を柔軟に変更できる「スケールイン/スケールアウト」の機能があります。
「○時~×時まで3台にする」といった時間をトリガーとする場合はシンプルですが、メトリクスによってスケールルールを設定する場合、用語が多く若干わかりにくい部分もあります。また、以前はスケールルールは App Service プランのメトリックのみ使用できましたが、現在は任意の Azure リソースのメトリックが使用可能です。
上記を踏まえ、本記事ではオートスケールの項目や設定全般について記述していきます。
スケーリング条件とスケジュール
オートスケールを実施するには、まずスケーリング条件の作成とそのスケジュールを設定します。
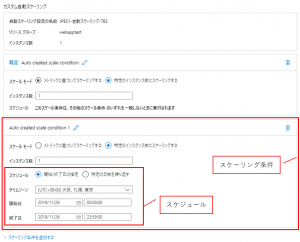
以下に各項目と説明を記載します。
スケーリング条件(プロファイル)
- 複数設定可能
- ルールに合致しない場合、既定ルールが実行
スケジュール
- 開始/終了日の指定
- 開始日時/終了日時を直接指定
- 特定の日数(=曜日)を繰り返す
- 曜日と開始時刻/終了時刻を指定
複数プロファイルがある場合の優先順位
- 開始日時/終了日時指定プロファイル
- 特定の曜日を繰り返す定期的プロファイル
- 既定プロファイル
- 複数ある場合、プロファイルの条件が満たされると、それより下位の条件はチェックされません。
- 同じスケジュール日時で設定した場合、上位に存在する条件のみ評価・実行されます。
スケールモードとスケールルール
次に、作成したスケジュールのスケールモードとスケールルールを設定します。以下に各項目と説明を記載します。
スケールモード
- 特定のインスタンス数にスケーリングする
- スケジュールされた日時にスケーリングする
- メトリックに基づいてスケーリングする
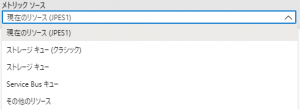
-
- メトリックソース
- AppService プラン
- AppService プランのメトリックに基づいたルール
- ストレージキュー(クラシック)
- ストレージキュー
- Service Bus キュー
- キューのメッセージ数に基づいたルール
- キューに処理を溜める場合に使用
- その他のリソース
- Azure リソースのメトリックに基づいたルール
- 無関係なリソースのメトリックによる設定も可能
- AppService プラン
- メトリックソース
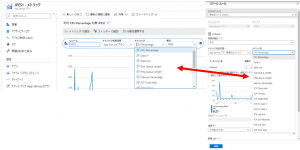
特に項番5の「その他のリソース」は、上図のようにメトリックに表示できるものがスケールルールにも使用可能となっています。代表的なメトリックを抜き出してみます。
AppService プランの主なメトリック
|
No |
メトリック名 |
単位 |
集計の種類 |
説明 |
|
1 |
CpuPercentage |
% |
平均 |
プランの全インスタンスで使用された平均 CPU |
|
2 |
MemoryPercentage |
% |
平均 |
プランの全インスタンスで使用された平均メモリ |
|
3 |
DiskQueueLength |
Count |
平均 |
ストレージのキューに登録された読み取り要求と書き込み要求の平均数。 多い場合、過剰なディスク I/O によってアプリの速度が低下している可能性がある。 |
|
4 |
HttpQueueLength |
Count |
平均 |
処理される前にキューで待つ必要があった HTTP リクエストの平均数。 これが多い、増加していることはプランに大きな負荷がかかっている事を意味する。 |
AppService の主なメトリック
|
No |
メトリック名 |
単位 |
集計の種類 |
説明 |
|
1 |
CpuTime |
Seconds |
合計 |
アプリで消費された CPU の量 (秒) |
|
2 |
Requests |
Count |
合計 |
結果として返された HTTP 状態コードを問わない、要求の合計数 |
|
3 |
MemoryWorkingSet |
Bytes |
平均 |
アプリで使用されている現在のメモリ量 (MiB) |
|
4 |
AverageMemoryWorkingSet |
Bytes |
平均 |
アプリで使用された平均メモリ量 (MiB) |
|
5 |
AverageResponseTime |
Seconds |
平均 |
アプリが要求に応答するのに要した平均時間 (秒) |
Application Insights の主なメトリック
|
No |
メトリック名 |
単位 |
集計の種類 |
説明 |
|
1 |
Browser page load time |
ミリ秒 |
平均、最小、最大 |
ブラウザーのページ読み込み時間 |
|
2 |
Page load network connect time |
ミリ秒 |
平均、最小、最大 |
ページ読み込みのネットワーク接続時間 ※Application Insights JavaScript SDK にて取得 |
|
3 |
Receiving response time |
ミリ秒 |
平均、最小、最大 |
受信側の応答時間 ※Application Insights JavaScript SDK にて取得 |
|
4 |
HTTP request execution time |
– |
– |
HTTP リクエスト実行時間 |
|
5 |
HTTP request rate |
– |
– |
HTTP リクエスト数/秒 |
|
6 |
Server requests |
– |
– |
サーバー要求 |
|
7 |
Server response time |
– |
– |
サーバー応答時間 |
|
8 |
Page view load time |
– |
– |
ページ ビューの読み込み時間 |
|
9 |
Page views |
– |
– |
ページ ビュー |
その他のメトリックの表示名と説明は以下サイトをご参照ください。
[Azure App Service のアプリの監視]-[メトリックを理解する]
https://docs.microsoft.com/ja-jp/azure/app-service/web-sites-monitor#understand-metrics
[Azure Monitor のサポートされるメトリック]
https://docs.microsoft.com/ja-jp/azure/azure-monitor/platform/metrics-supported
[Application Insights ログベースのメトリック]
https://docs.microsoft.com/ja-jp/azure/azure-monitor/platform/app-insights-metrics
※Application Insights のカスタムメトリック (ユーザーによって作成されたメトリック) でのオートスケールにも対応しています。
※App Service プランのメトリックの TCP 各値は不明であるため使用しないことを推奨します。
[What are the TCP metrics available for Web Apps?]
https://github.com/MicrosoftDocs/azure-docs/issues/34079
スケールの判断基準 (Criteria) について
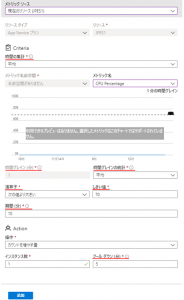
期間
- 指定した分数遡り、時間の集計を評価する。
- キューに関しては履歴がなく期間は無視される。
時間の集計
- 「期間」で定めた時間の中で時間グレイン単位で取得した値の集計方法。
- 個別値は以下を参照。一般的な統計は平均。
- 平均…取得した値の平均値。
- 最小…取得した値の中での最小値。
- 最大…取得した値の中での最大値。
- 合計…取得した値の合計値。
キューの長さ等を確認したいときに使用する値で
その他のスケールルールのしきい値としては適さない。 - 最終…取得した値の中での最終(一番直近)の値。
- カウント…取得した値の個数。
障害検知等での利用用途はあるが、スケールルールのしきい値としては適さない。
時間グレイン
- メトリックのサンプリング期間。
- 選択されたメトリックでサポートされている最も細分度の細かいグレインから自動的に選択される。
時間グレインの統計
- 時間グレインの集計方法。
- 個別値は以下を参照。一般的な統計は平均。
- 平均…取得した値の平均値。
- 最小…取得した値の中での最小値。
- 最大…取得した値の中での最大値。
- 合計…取得した値の合計値。
キューの長さ等を確認したいときに使用する値でスケールルールのしきい値としては適さない。
演算としきい値
- オートスケールを実行する判別値。
クールダウン
- スケール操作の後にもう一度スケールするまでの待ち時間。
- クールダウンが 10 分間の場合、スケール操作が発生したばかりの場合、10 分間経過するまで実行しない。
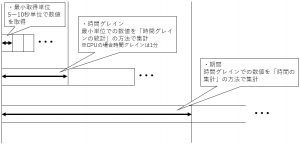
最小取得単位・時間グレイン・期間の考え方
時間グレインの説明で出てきた「最小取得単位」とは、Azureが内部的に取得する最も小さい範囲でのメトリックログです。範囲は5~10秒程度の範囲となりますが、これはポータルから確認できません。App Serviceのダッシュボードなどから確認できるメトリックのグラフなどでの最小単位は1分単位の値で、これは1分間に取得した最小取得単位の平均値になります。
それぞれの関係を以下イメージ図として記載します。
参考URL
[自動スケールのスケールルールについて]
https://blogs.msdn.microsoft.com/jpcie/?p=1315
項目と設定については以上ですが、下記に自動スケールの考慮事項を記載します。
自動スケールについての考慮事項
自動スケールには以下のような推定動作があり、これを考慮せずに設定してしまうと上手く動作しない場合があります。
推定動作
- スケールダウンを実行する前に、スケールインした場合の最終状態の推定を試みる。
- この動作はスケールイン後すぐにスケールアウトする無限ループを防ぐためである。
- 推定動作により、スケールダウンが実行されないことがある。
- 例)推定動作によりスケールダウンしないルール
- CPU 使用率が 80 以上のときにインスタンスを 1 つ増やす
- CPU 使用率が 60 以下のときにインスタンスを 1 つ減らす
- 推定動作の流れ
- 最初に 2 つのインスタンスがあるとした場合、全インスタンスの平均 CPU 使用率が 80% に達すると、3 つ目のインスタンスが追加されます。
- CPU 使用率が 60% に低下したとき、スケールインした場合の最終状態が推定されます。CPU 使用率は、60% × 3 (現在のインスタンス数) でトータル 180% となります。2 つにスケールダウンしたとき、180 / 2 で CPU 使用率は 90% と推定されるためスケールインは実行されません。
- 次回チェック時に CPU 使用率が 50% に低下していると、 再び推定が行われます。50% × 3 インスタンス = 150 / 2 インスタンス = 75% となり、スケールアウトのしきい値である 80% を下回っているため、2 つのインスタンスにスケールインされます。
まとめ
- スケールアウトとスケールインに同じしきい値を使用する場合は、推定動作に留意する必要があります。
- スケールアウトとスケールインのしきい値に十分な差を付けましょう。
- キャパシティ不足ないしは余剰を検知するためにはメトリック収集と監視が重要です。
- 高負荷時のシステム特性を見極め、適切なメトリックを設定するためには負荷テストが有用です。
- 適切なメトリックはシステム特性によって大きく異なります。
- メモリーを大量に消費するアプリケーションにおいては、高負荷状態になるとメモリーが逼迫しスループットやレスポンスタイムの悪化が発生することが予想されます。一方、CPU の使用率は低いままであれば、CPU Percentage というメトリックは役に立ちません。
- 高負荷時のシステム特性を見極め、適切なメトリックを設定するためには負荷テストが有用です。
参考URL
[自動スケールのベスト プラクティス]
https://docs.microsoft.com/ja-jp/azure/azure-monitor/platform/autoscale-best-practices
[Azure App Service の自動スケールと負荷テスト]
https://blogs.msdn.microsoft.com/ainaba-csa/2017/04/03/azure-app-service-auto-scale-and-load-test/
以上、参考にして頂ければと思います。
 (この記事が参考になった人の数:7)
(この記事が参考になった人の数:7)