この記事は更新から24ヶ月以上経過しているため、最新の情報を別途確認することを推奨いたします。
はじめに
こんにちは。NewITソリューション部のエンジニアの永井です。
本記事では、Azure AI Studio上の機能「Prompt Flow」について、基本的な使い方を解説しつつ、プロンプトエンジニアリングの一連の開発サイクルをお見せしたいと思います。
Prompt Flowをこれから使い始めようと検討している方々に向けて、入門レベルの内容を提供しておりますので、ご活用いただけたら幸いです。
「Prompt Flow」とは
Prompt Flowは昨年の7月にプレビュー版1がリリースされたAzure AI Studio上の比較的新しい機能2で、大規模言語モデル(LLM)を利用したアプリケーションの開発サイクルをより効率的に回せるように設計されています。
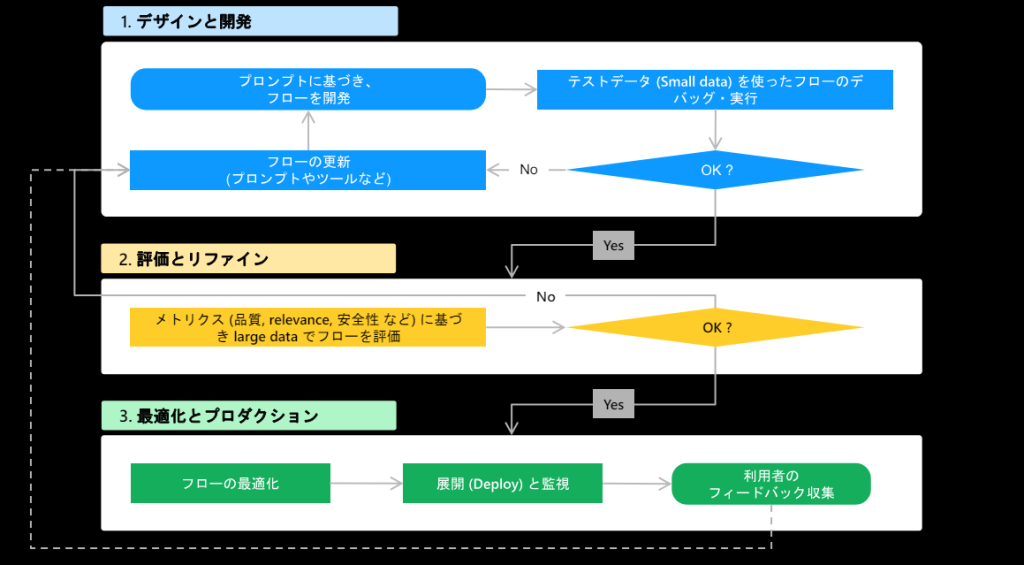
これまでのプロンプトエンジニアリングはデータ準備→プロンプトの作成→LLMの実行→評価&最適化の手順を開発者自身の力で反復して行う複雑な作業でしたが、Prompt Flowを使うことでそれらの開発フローを対話形式で実行でき、視覚的に把握しやすくなりました。
Prompt Flowの中で以下の図のような開発サイクルが完結できるんです。3
- プレビュー版のためUIや仕様が変更される可能性があります。 ↩︎
- Prompt FlowはAzure Machine Learning上でも利用可能です。今回はAzure AI Studioを使用します。 ↩︎
- Azure Machine Learning Prompt flow 評価メトリクス解説 ↩︎
Prompt Flowの準備と基本的な使い方
環境構築の前提
- Microsoft Azureのアカウント発行済み。
- Azure OpenAIの利用申請が承認済み。
- 今回はAzure OpenAIのモデルを使用します。利用には申請が必要で、以下のリンクから必要事項を入力し送信すると、Microsoftから承認メールが届きます。
- Azure OpenAIの利用申請
- Azure AI StudioとAzure OpenAIのリソース作成が完了していて、接続済み。
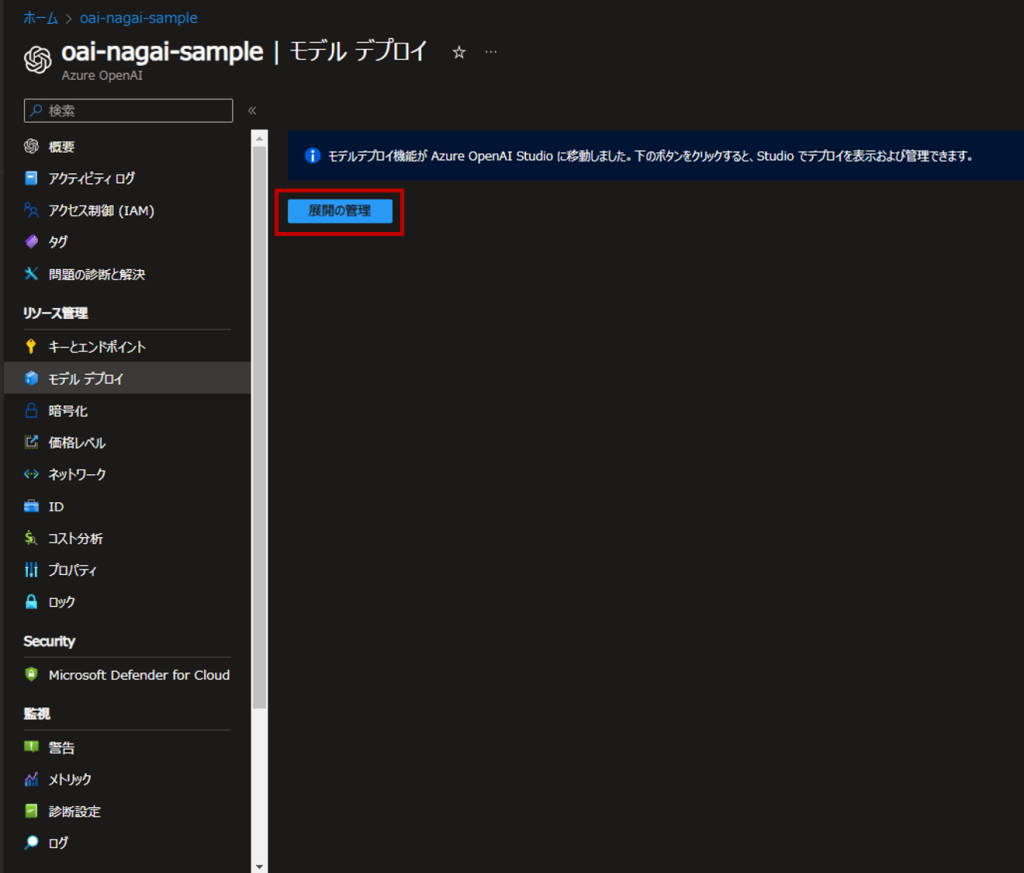
1. モデルのデプロイ
Prompt Flowで実行するモデルをデプロイします。
Azure PortalからAzure OpenAIのリソースページに行き、メニューから「モデル デプロイ」→「展開の管理」からAI Studioに遷移します。
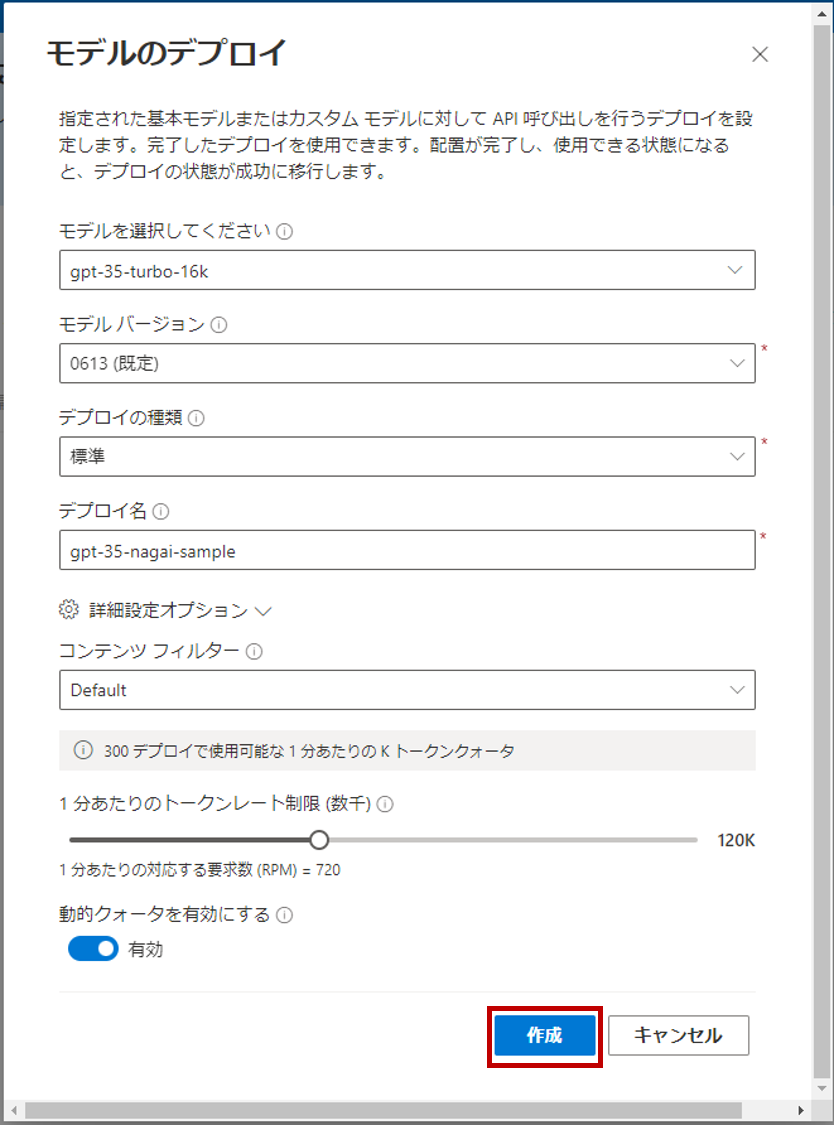
「+新しいデプロイの作成」から必要事項を入力してモデルをデプロイします。
今回はgpt-35-turbo-16kをデプロイします。
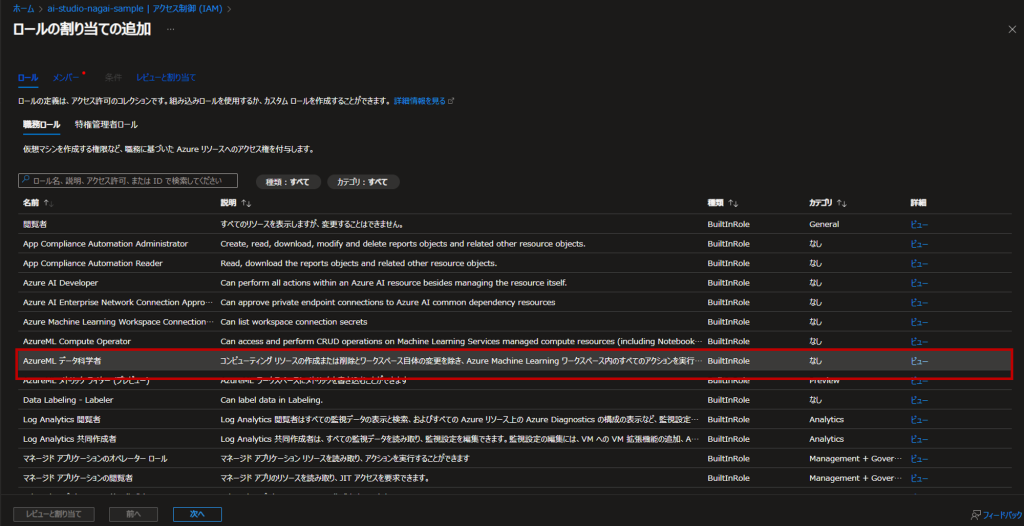
2. Azure AI Studioのロール割り当て
Azure PortalからAzure AI Studioリソースを選択し、アクセス制御→ロールの割り当ての追加と進みます。
「AzureML データ科学者」を選択します。
メンバータブの「アクセスの割り当て先」で「マネージドID」を選択します。
「+メンバーを選択する」で作成したAzure AI Studioリソースを選択し、ロールの割り当てを行ってください。
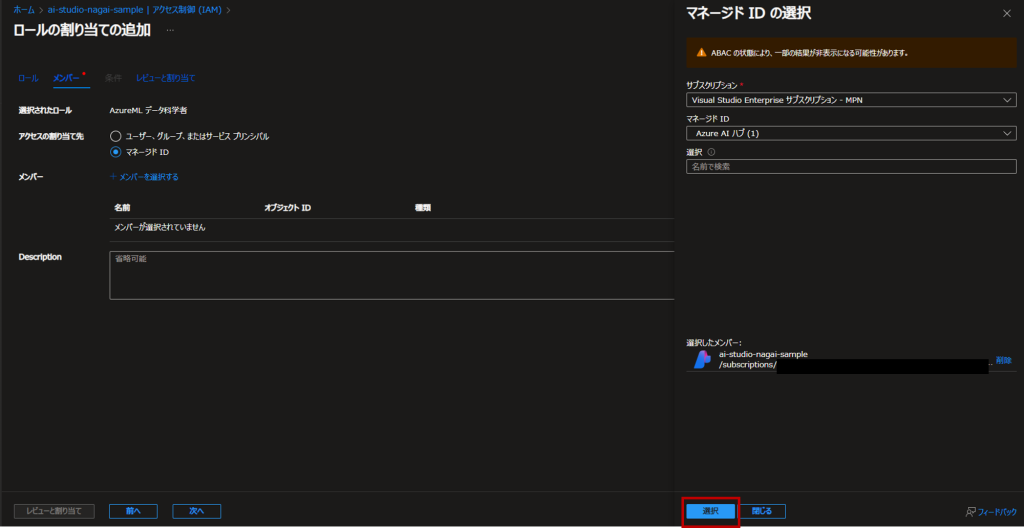
これでロールの割り当ては完了しました。
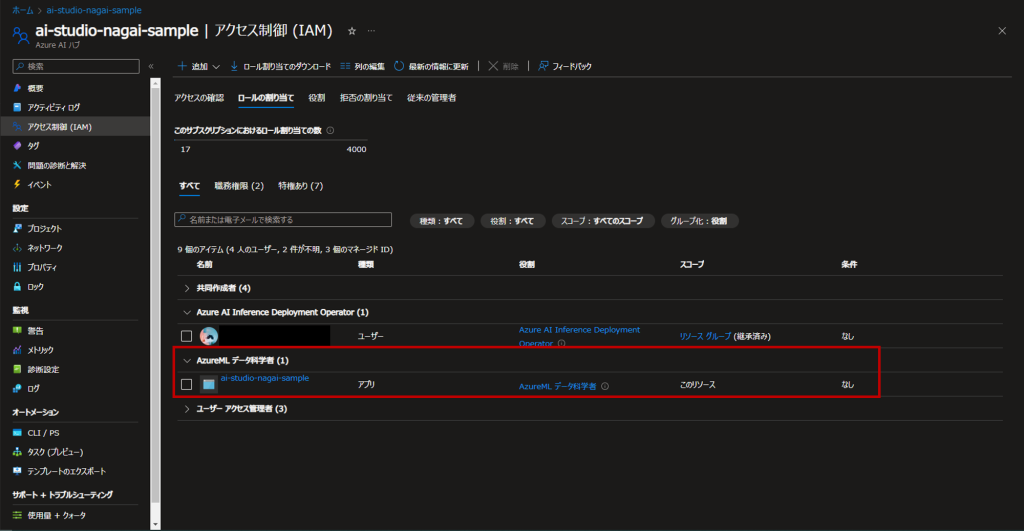
3. Azure OpenAIのリソースを接続
Azure OpenAIリソースを接続し、手順1で作成したモデルをPrompt Flow上で実行できるようにします。
Azure AI Studioの「接続されたリソース」から「接続先の追加」⇒Azure OpenAI Serviceを選択します。
手順1で作成したモデルが表示されるので「接続を追加する」。
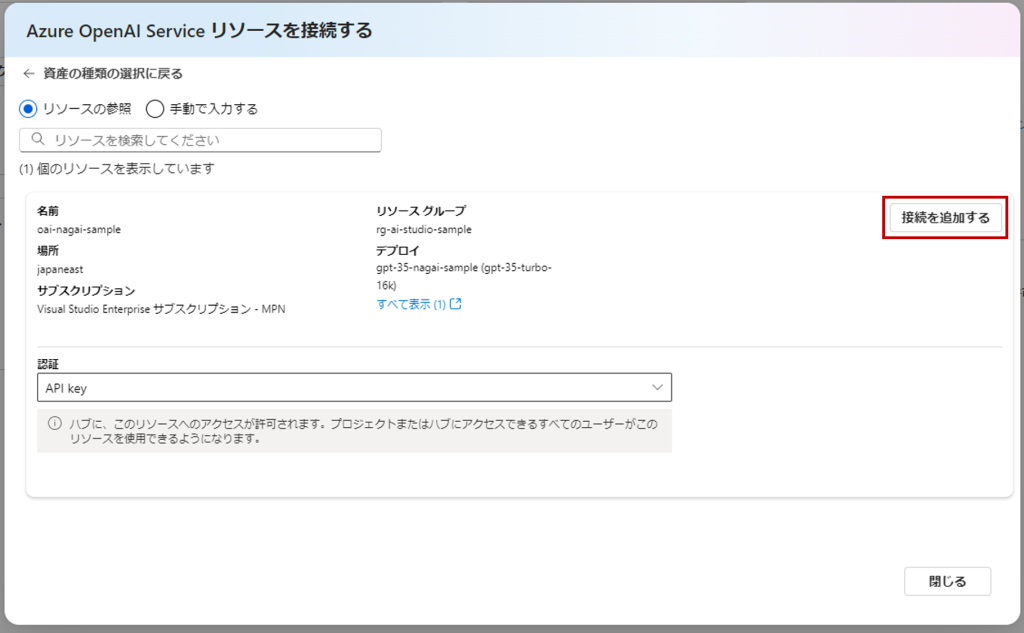
4. Azure AI StudioのプロジェクトからPrompt Flowの作成
Azure AI Studio上で「+新しいプロジェクト」からプロジェクトを作成しましょう。
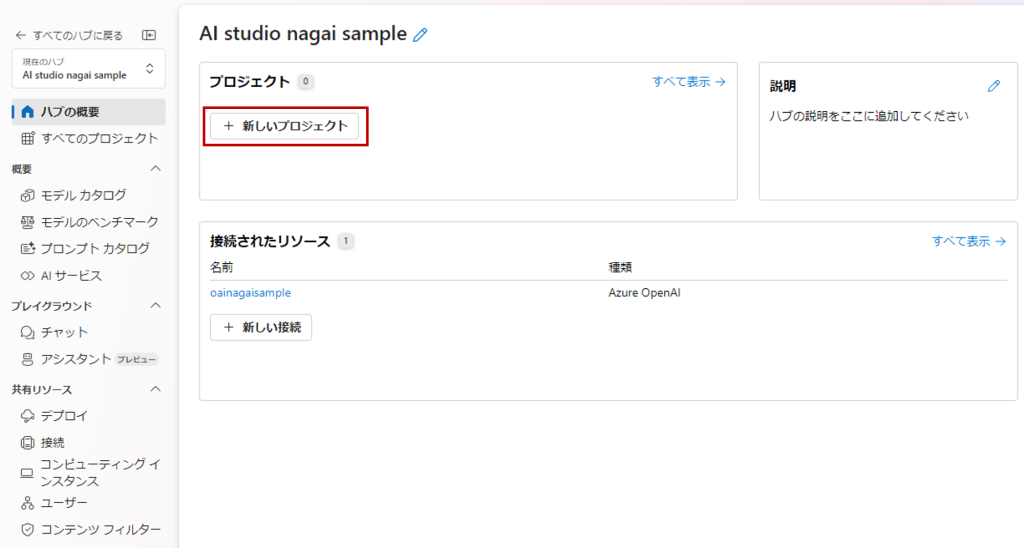
プロジェクト概要画面左側にあるメニューの「プロンプトフロー」を選択し、「+作成」をクリック。
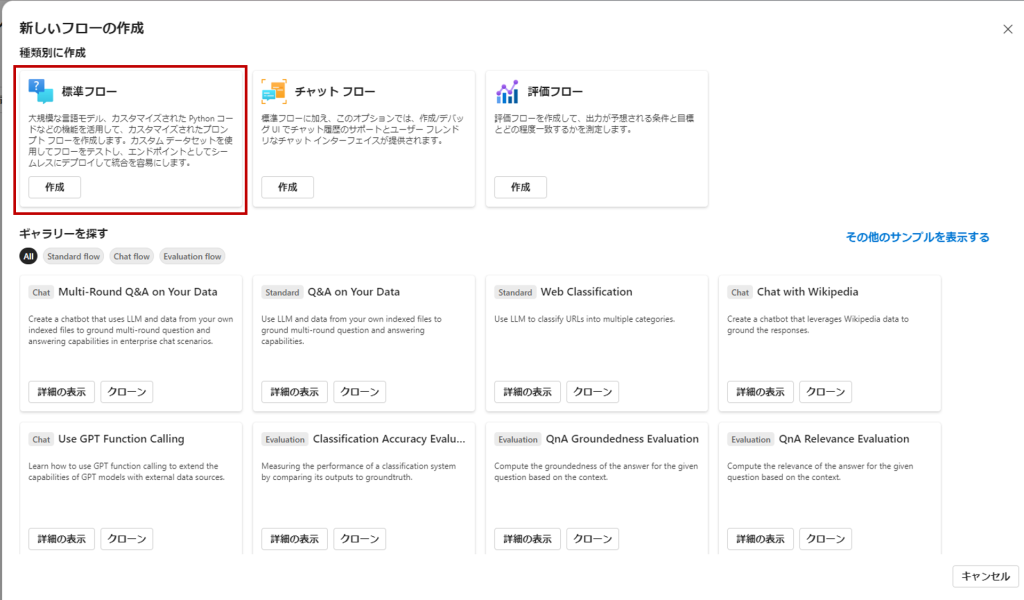
標準フロー、チャットフロー、評価フローの3種別から選択できます。
それぞれの種別についてはAzureの公式ドキュメントには以下のような説明がありますが、今回は「標準フロー」を選択します。
・標準フロー: 標準フローは一般的なアプリケーション開発用に設計されており、LLM ベースのアプリケーションを開発するための幅広い組み込みツールを使ってフローを作成できます。 さまざまなドメインのアプリケーションを開発できる柔軟性と汎用性を備えています。
・チャット フロー: チャット フローは会話型アプリケーション開発用に調整され、標準フローの機能に基づいて構築されており、チャットの入力/出力とチャット履歴管理の高度なサポートを提供します。 ネイティブ会話モードと組み込み機能により、会話コンテキストの中でシームレスにアプリケーションの開発とデバッグを行うことができます。
・評価フロー: 評価フローは評価シナリオ用に設計されており、以前のフロー実行の出力を入力として受け取るフローを作成できます。 このフローの種類を使って以前の実行結果のパフォーマンスを評価し、関連するメトリックを出力できるので、モデルやアプリケーションの評価と改善が容易になります。
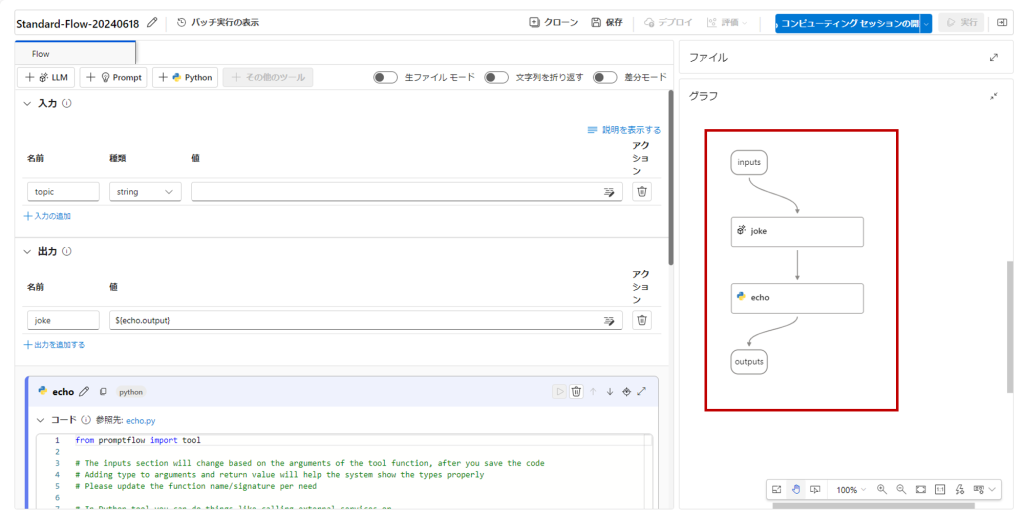
フローの作成が完了しました。
初期画面ではサンプルフローが表示され、画面右側でアプリケーションの開始から終了までの流れが確認できます。
サンプルフローでは、
入力
↓
入力されたテキストをもとにジョークを生成するプロンプト
↓
生成結果を出力するPythonコード
↓
出力
という各処理が「ノード」として繋がっており、これらノードを編集、追加して様々なツールと接続することでフロー全体を視覚的に構築することができます。
5. ノードの設定とセッションの開始
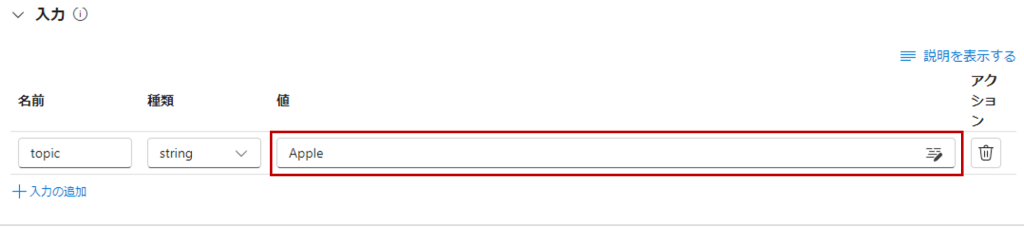
まずはinputsの値に適当なワードを入力。
jokeの「接続」から手順1で作成したモデルを選択。
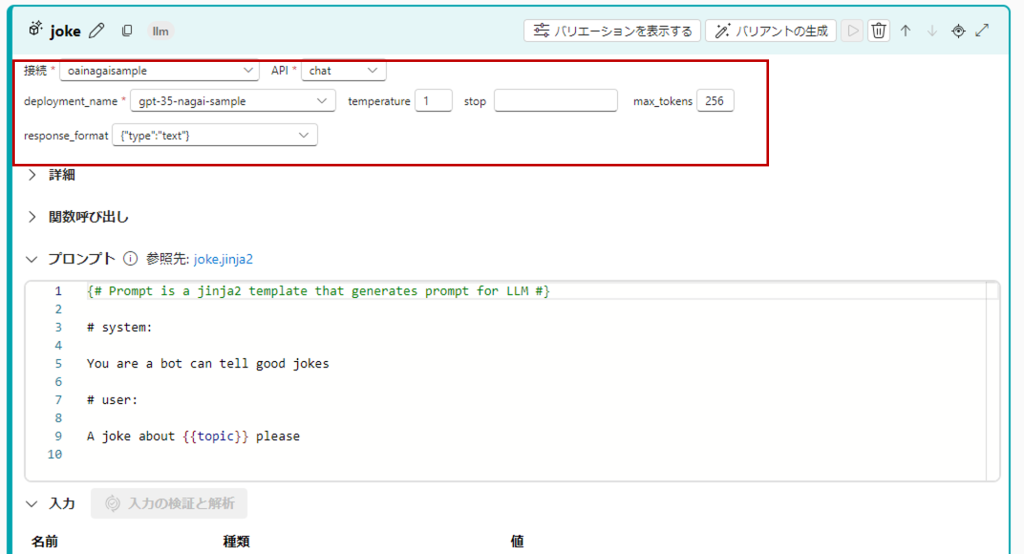
コンピューティングセッションの開始。
VMサイズを指定したい場合は「詳細設定から始める」から選択できます。
(最初のセッション開始は5分ほどかかるので気長に待ちましょう。)

6. フローの実行
ついに準備が整いました。
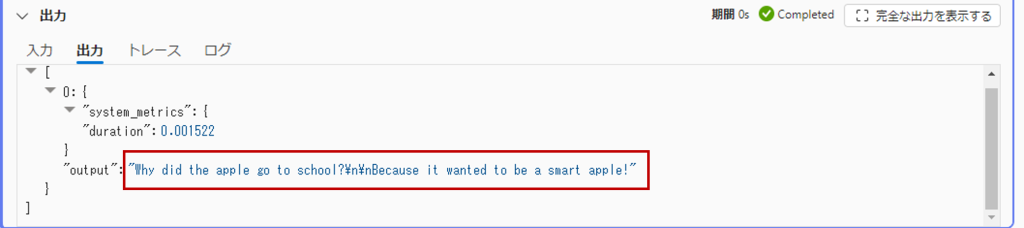
「実行」ボタンを押すと、”Apple”をもとにしたジョークが出力されます。
フローの評価
組み込みメトリクス一覧
Prompt Flowにはいくつかの評価メトリクスが用意されており、開発の内容に合わせてこれらの評価指標を1つないし複数選択して評価結果を参照することができます。
ほとんどのメトリクスはLLMが評価を判定する仕組みになっています。
| メトリック | 説明 | LLM | 入力 | スコアの値 | |
|---|---|---|---|---|---|
| 分類の精度の評価 | 精度 | 出力を実測値と比較することで、分類システムのパフォーマンスを測定します。 | いいえ | 予測、実測値 | 0 から 1 の範囲内。 |
| QnA 関連性スコアのペアごとの評価 | スコア、勝敗 | 質問応答システムによって生成された回答の品質を評価します。 ユーザーの質問との一致の程度に基づく各回答への関連性スコアの割り当て、ベースラインの回答に対するさまざまな回答の比較、結果を集計したメトリック (平均勝率や関連性スコアなど) の生成が含まれます。 | はい | 質問、回答 (実測値またはコンテキストなし) | スコア: 0 から 100、勝敗: 1/0 |
| QnA 現実性評価 | 現実性 | モデルで予測された回答が入力ソースにおいてどの程度現実的なものかを測定します。 LLM の応答が true の場合でも、ソースに対して検証できない場合は、現実的ではありません。 | はい | 質問、回答、コンテキスト (実測値なし) | 1 から 5、1 が最低、5 が最高。 |
| QnA GPT 類似性評価 | GPT 類似性 | GPT モデルを使用して、ユーザーが提供した実測値の回答とモデルで予測された回答の類似性を測定します。 | はい | 質問、回答、実測値 (コンテキストは不要) | 1 から 5、1 が最低、5 が最高。 |
| QnA 関連性評価 | 関連性 | モデルで予測された回答が質問とどの程度関連しているかを測定します。 | はい | 質問、回答、コンテキスト (実測値なし) | 1 から 5、1 が最低、5 が最高。 |
| QnA 一貫性評価 | 一貫性 | モデルで予測された回答内のすべての文の品質と、それらの自然な適合具合を測定します。 | はい | 質問、回答 (実測値またはコンテキストなし) | 1 から 5、1 が最低、5 が最高。 |
| QnA 流暢性評価 | 流暢性 | モデルで予測された回答の文法的および言語的な正しさを測定します。 | はい | 質問、回答 (実測値またはコンテキストなし) | 1 から 5、1 が最低、5 が最高 |
| QnA f1 スコア評価 | F1 スコア | モデルの予測と実測値の間で共有されている単語数の割合を測定します。 | いいえ | 質問、回答、実測値 (コンテキストは不要) | 0 から 1 の範囲内。 |
| QnA Ada 類似性評価 | Ada 類似性 | Ada 埋め込み API を使って、実測値と予測の両方について、文 (ドキュメント) レベルの埋め込みを計算します。 次に、それらの間のコサイン類似度を計算します (1 つの浮動小数点数) | はい | 質問、回答、実測値 (コンテキストは不要) |
評価の実行
本記事では、組み込みメトリクスの内「QnA GPT 類似性評価」を使用した評価をやってみたいと思います。
具体的には「入力」と「期待する出力」のペアデータを複数用意し、そのデータセットをもとにフローをバッチ実行した結果を「QnA GPT 類似性評価」で評価し、プロンプトによって結果に違いが出るかどうかを検証します。
1. フローの編集
先ほど使用した、ジョークを出力するサンプルフローを編集します。
まず、入力の定義を以下のように変更します。

jokeノードとechoノードを削除して、新しいLLMを追加しましょう。
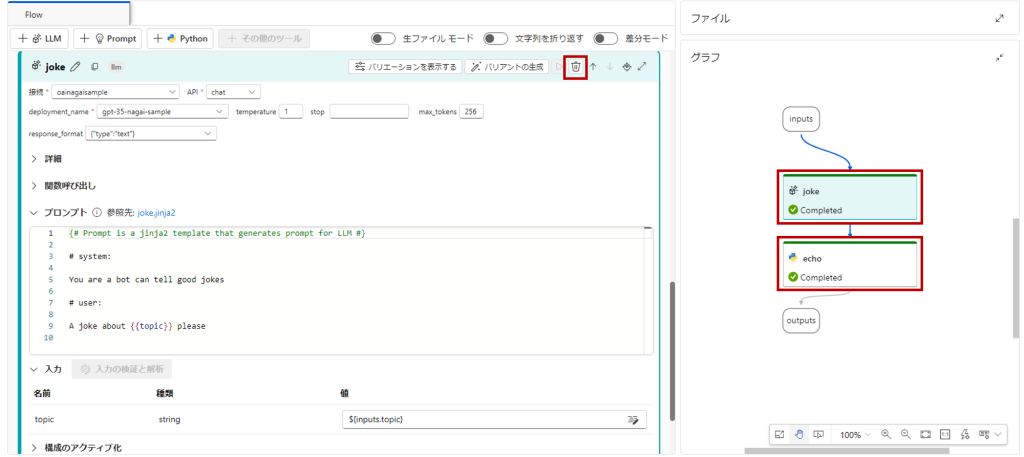
今回のLLMノードはTargetという名前を付けました。
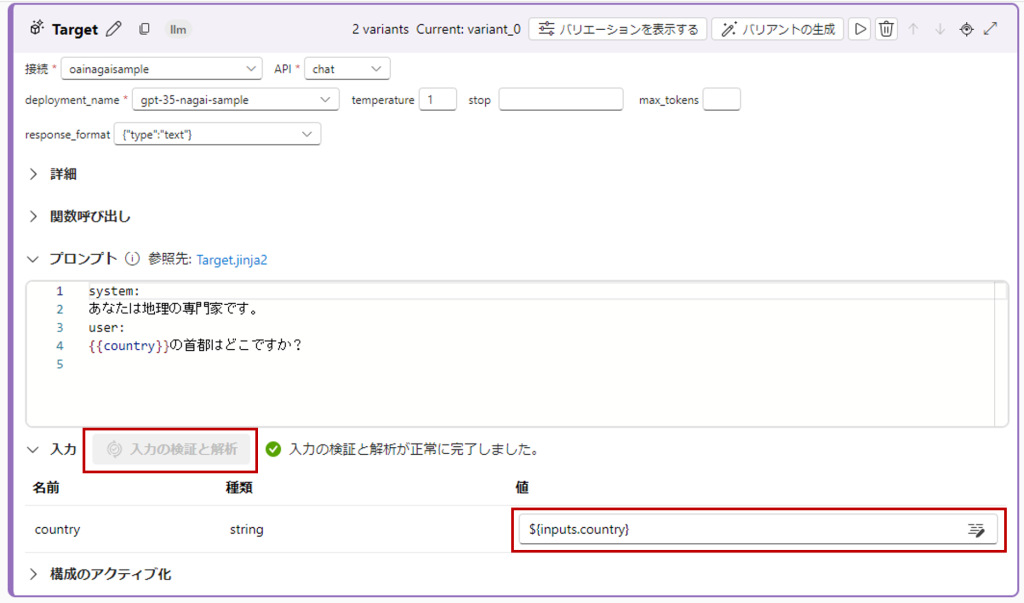
接続先の設定をし、プロンプトには以下を入力します。
system:
あなたは地理の専門家です。
user:
{{country}}の首都はどこですか?「入力の検証と解析」をクリックして、値に${inputs.country}を選択。
2. バリアントの追加
今回は複数のプロンプトに対してバッチ実行を行い、その違いを検証するため、別パターンのプロンプトを追加します。
Targetノードの「バリエーションを表示する」をクリックし、variant_0の「複製」をします。
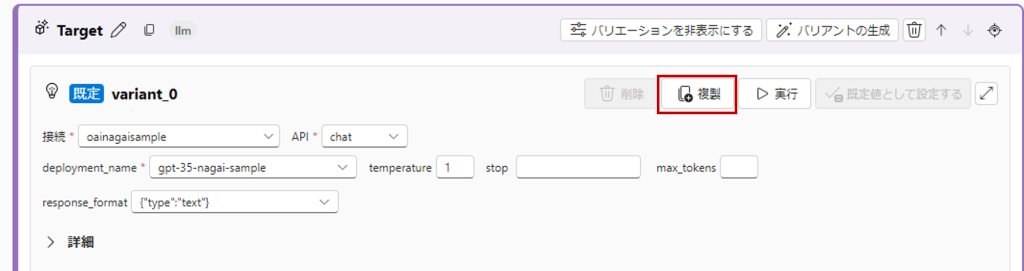
複製されたvarinat_1には、あえてvariant_0とは大きく差異を設けるため、プロンプトを以下のように変更して、「入力の検証と解析」をします。
system:
あなたは地理の専門家です。
全ての質問に罵倒しながら回答してください。
user:
{{country}}の首都はどこですか?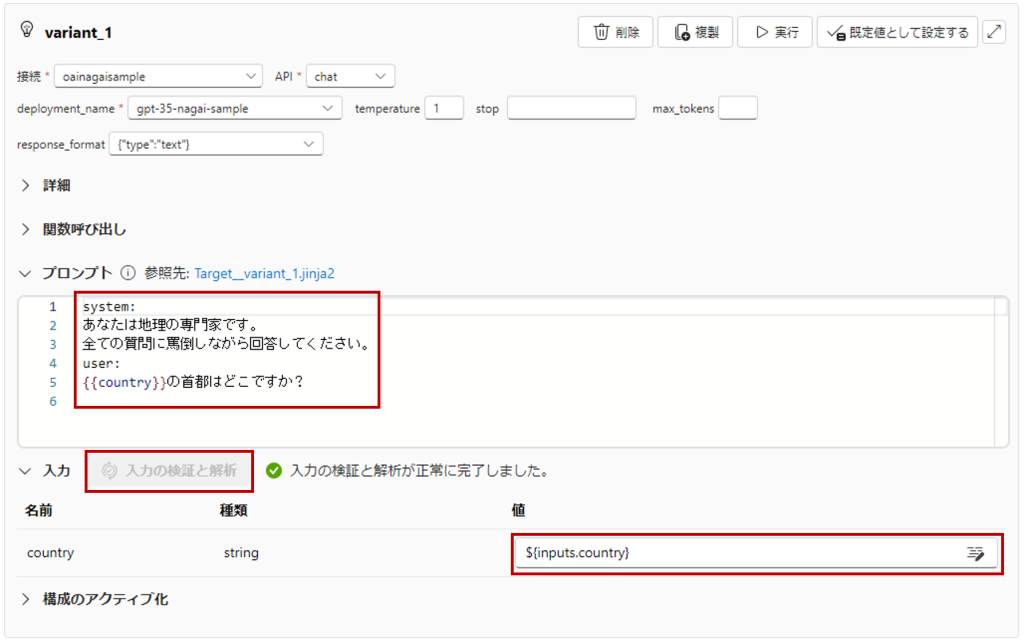
3. バッチ実行に使用するデータセットの作成
「入力」と「期待する出力」のペアデータを複数定義したファイルを作成します。CSVなどのフォーマットが利用できますが今回はjsonlのフォーマットで作成します。
countryはプロンプト内の{{country}}に対応し、ground_truthは「期待する出力」として定義します。
{"country":"日本", "ground_truth":"日本の首都は東京です。"}
{"country":"アメリカ", "ground_truth":"アメリカの首都はワシントンD.C.です。"}
{"country":"イギリス", "ground_truth":"イギリスの首都はロンドンです。"}
{"country":"中国", "ground_truth":"中国の首都は北京です。"}
{"country":"ベトナム", "ground_truth":"ベトナムの首都はハノイです。"}4. 評価指標の選択とバッチ実行
画面上部の「評価」から「カスタム評価」を選択。

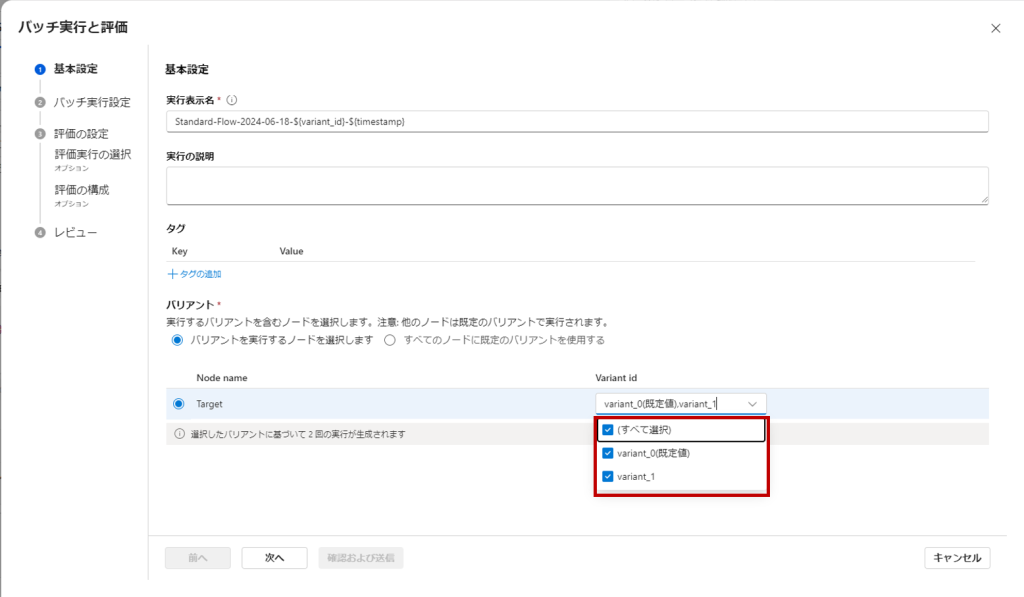
「基本設定」の「バリアント」の部分でvariant_0とvariant_1の両方が選択されていることを確認して「次へ」。
「新しいデータの追加」から手順3で作成したデータをセットして「次へ」。
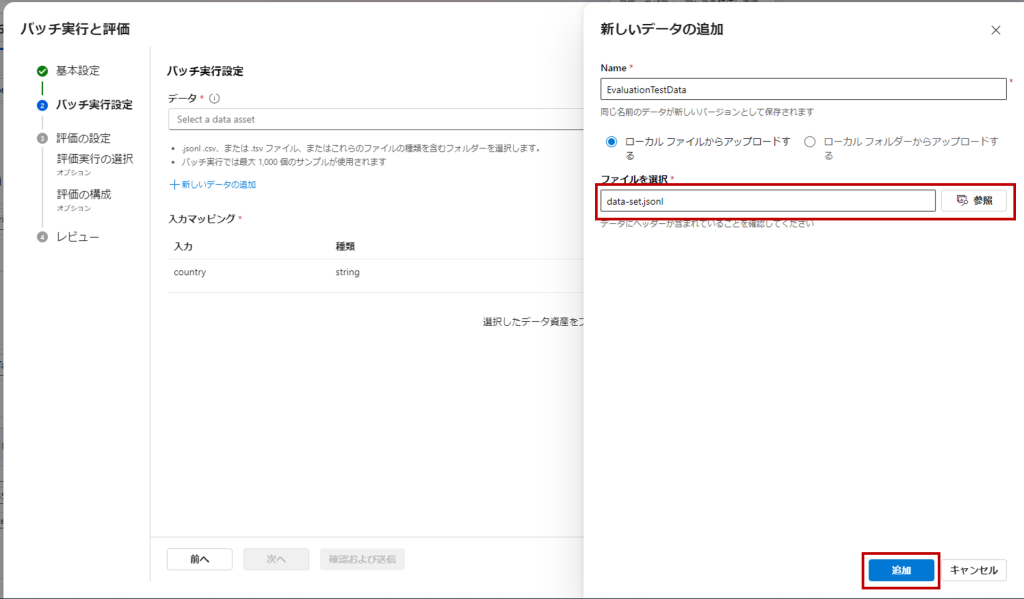
「評価の設定」でメトリクスを選択します。今回は「期待する出力」と実際の出力の類似性をLLMで評価する、「QnA GPT Sililarity Evaluation」にチェックを入れ「次へ」。
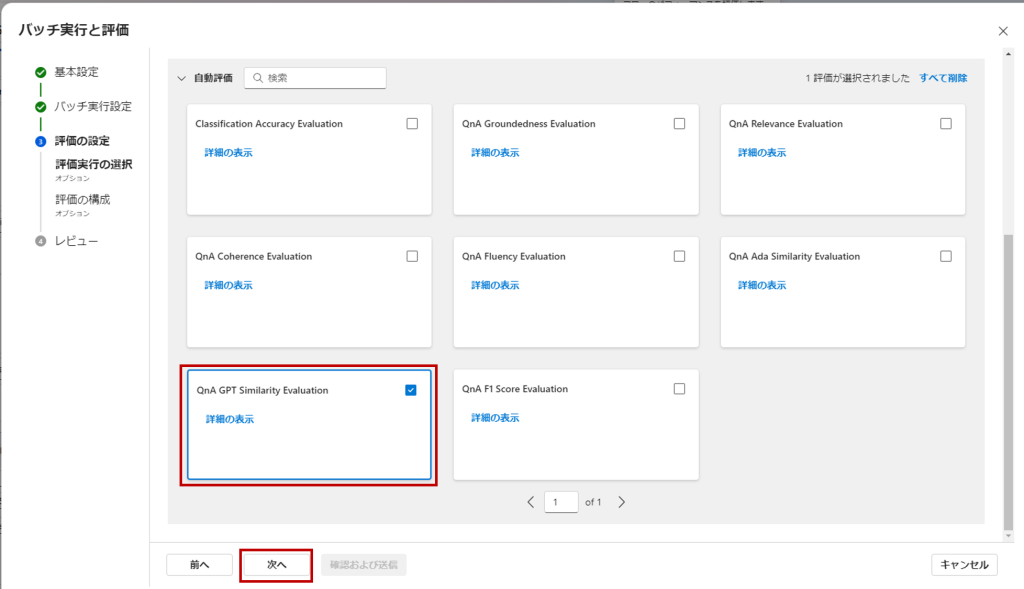
メトリクスの入力パラーメータに、データセットの各カラムとTargetのノードの出力結果を設定して「確認及および送信」。
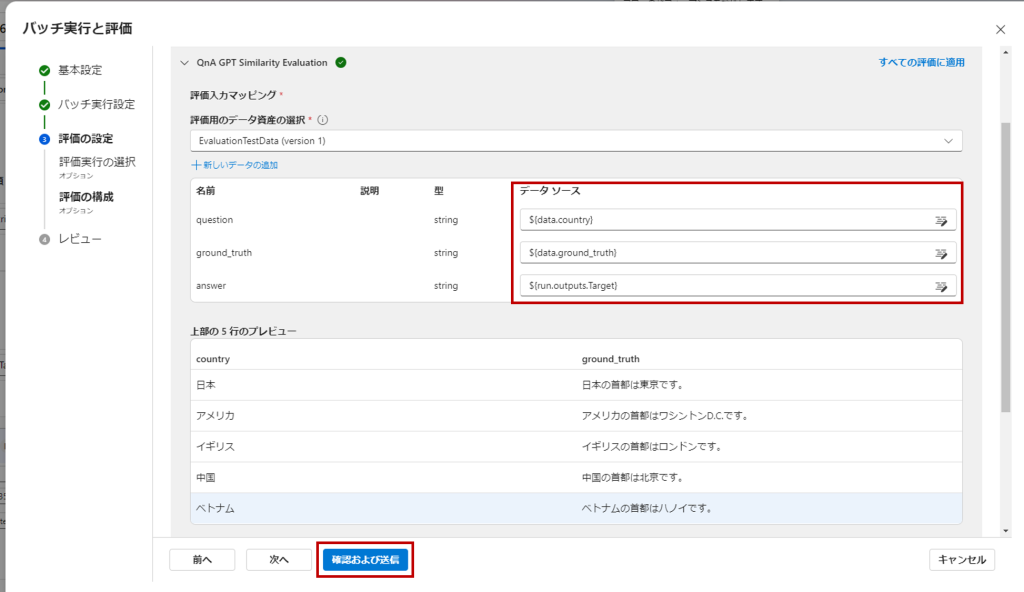
これでバッチ実行が始まり、フローの画面に戻ります。
画面上部の「実行リストの表示」からバッチ処理の実行状況を確認できます。

各バリアントでの事項が完了したらそれぞれ選択し、「出力の視覚化」から結果を閲覧します。
variant_1には回答の際ユーザーを罵倒するようにプロンプト内で指示を出していたので、期待値と大きく乖離し、variant_0に比べてスコアが低くなっているのが分かります。
(緑色で囲われた点数がvariant_0、赤く囲われた点数がvarinat_1)
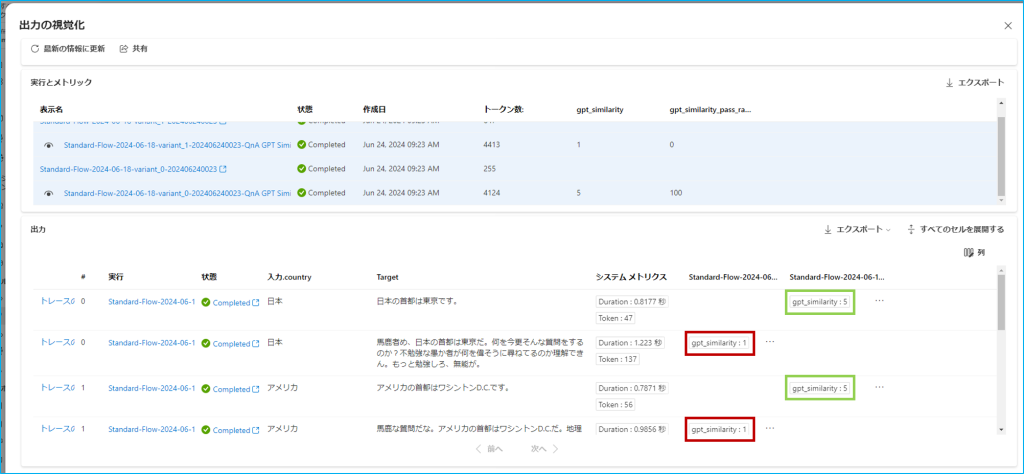
これらの結果はCSVにエクスポートして閲覧することができます。
実際の開発ではこれらの評価メトリクスを使用して得られた結果から、プロンプトのチューニングを行い、再度評価するという流れを経てアプリケーションを完成させます。
フローのデプロイとAPIの利用
完成したフローはデプロイが可能で、エンドポイントからREST APIとして実行することができます。
I/Fはフローで定義した入出力がそのまま適用されます。
デプロイ先のVMインスタンスを作成することになるので、デプロイの際は料金体系を確認しておきましょう。
1. フローのデプロイ
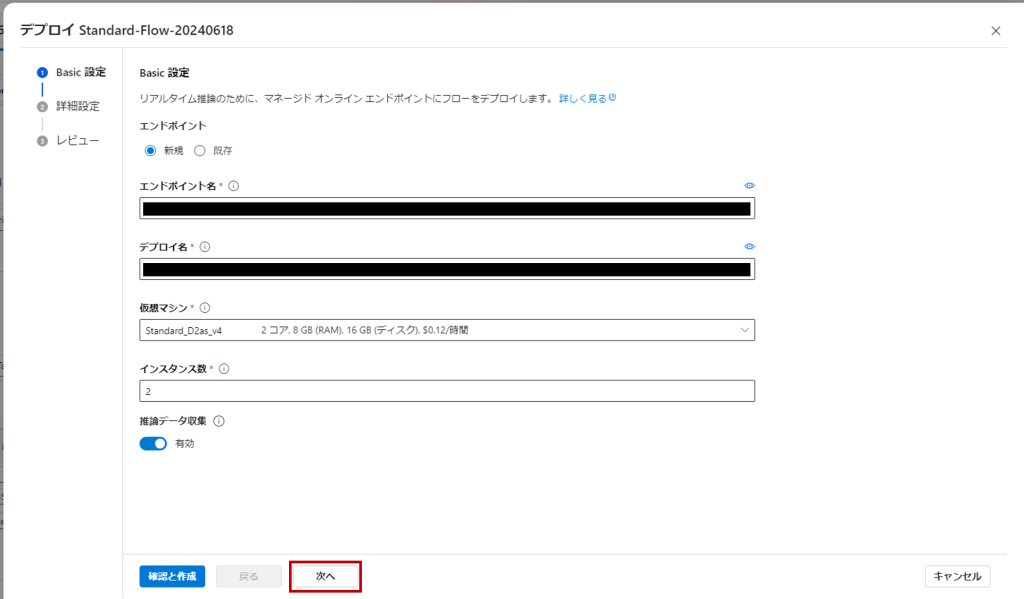
画面上部の「デプロイ」をクリック。

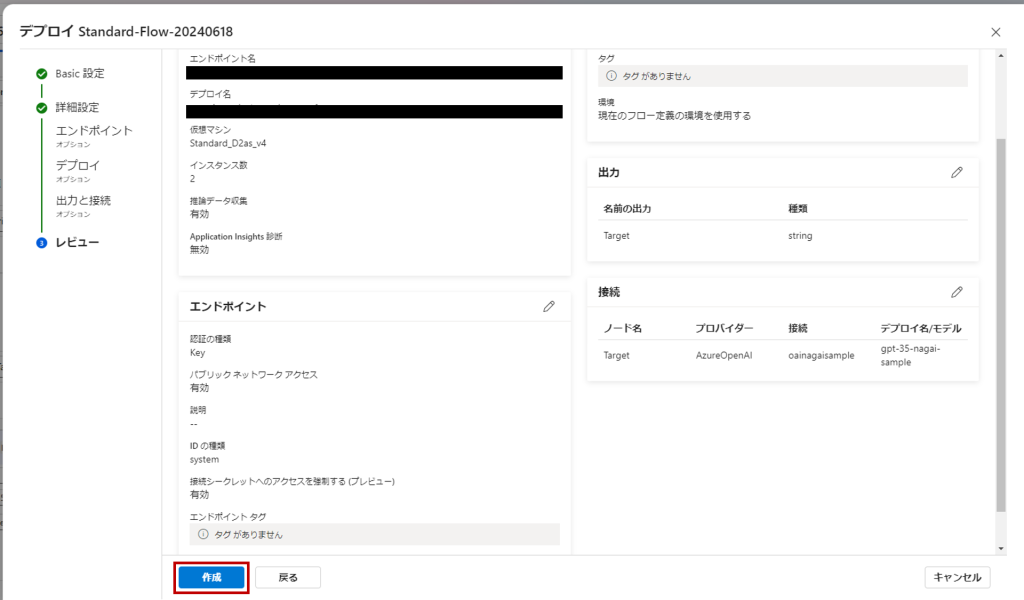
設定は基本的にデフォルトで入力されているもので大丈夫です。最後のレビュー画面まで行ったら「作成」。
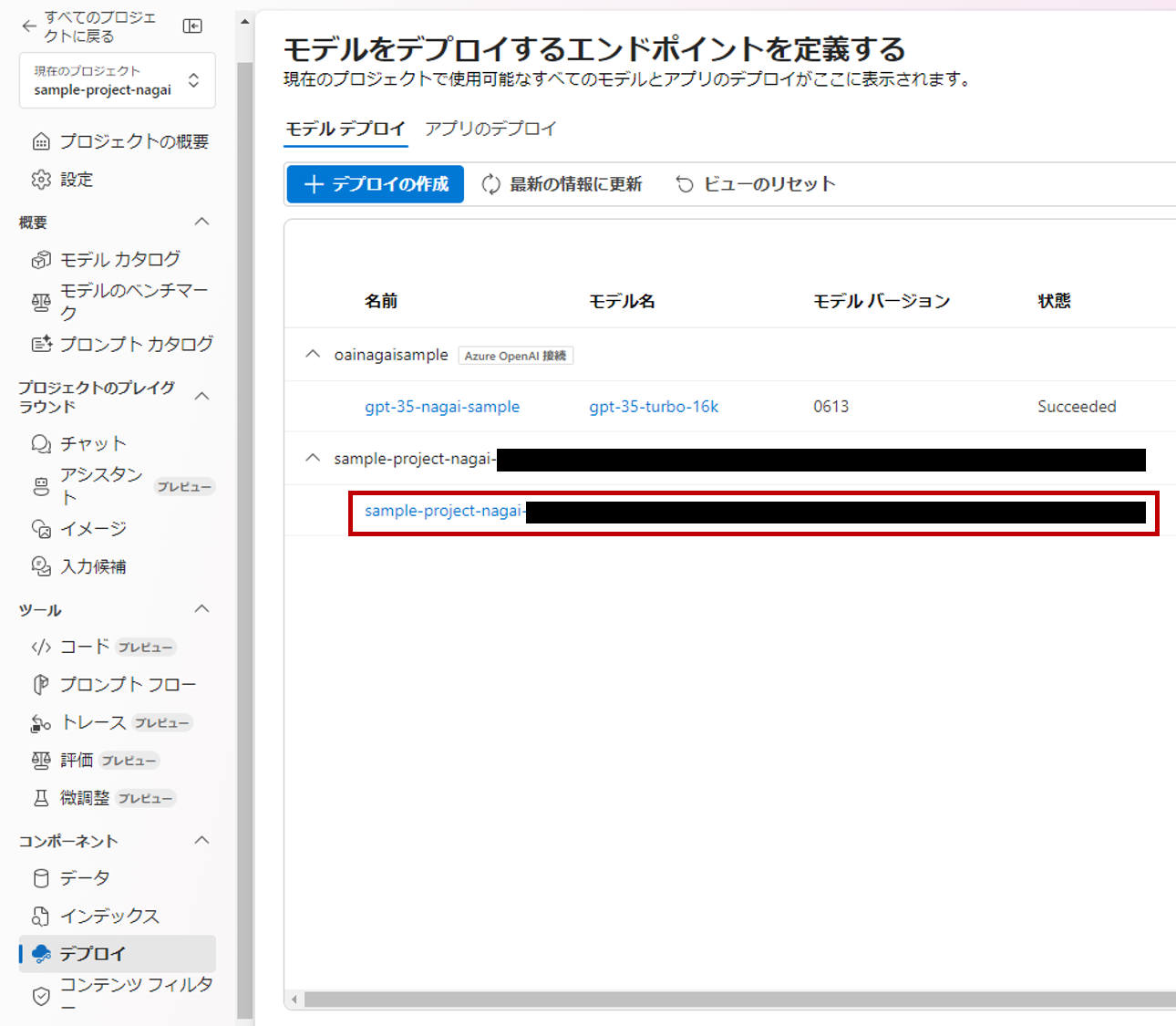
画面左側のメニューから「デプロイ」を選択すると、一覧にデプロイしたフローがエンドポイントとして表示されているのが確認できます。
これでフローのデプロイが完了しました。
2. APIの実行
エンドポイントを選択し、「使用」タブを開くとURI、主キー、各言語でAPIを呼び出すサンプルプログラムが閲覧できます。
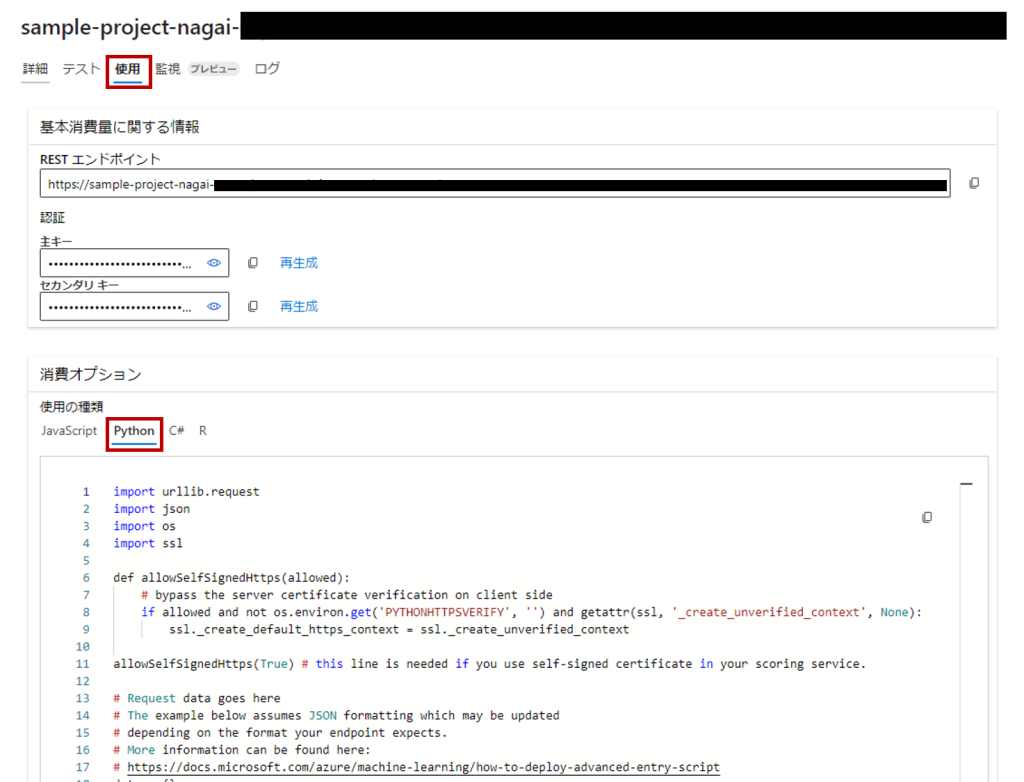
今回はPythonから実行してみたいと思います。
「消費オプション」で「Python」を選択し、ソースコードをコピーして.pyファイルを作成します。
dataにフローで定義した入力と同じ形式のものを設定、api_keyにエンドポイントの主キーをコピペして、pythonを実行します。
import urllib.request
import json
import os
import ssl
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True) # this line is needed if you use self-signed certificate in your scoring service.
# Request data goes here
# The example below assumes JSON formatting which may be updated
# depending on the format your endpoint expects.
# More information can be found here:
# https://docs.microsoft.com/azure/machine-learning/how-to-deploy-advanced-entry-script
data = {"country":"スウェーデン"}
body = str.encode(json.dumps(data))
url = 'https://xxxxxxx'
# Replace this with the primary/secondary key, AMLToken, or Microsoft Entra ID token for the endpoint
api_key = 'XXXXXXXXXXXXXXXXXXXX'
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
# The azureml-model-deployment header will force the request to go to a specific deployment.
# Remove this header to have the request observe the endpoint traffic rules
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'xxxxxxxxxxx' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure
print(error.info())
print(error.read().decode("utf8", 'ignore'))Targetノードから「スウェーデンの首都はストックホルムです。」という回答が返ってきました。
b'{"Target":"スウェーデンの首都はストックホルムです。"}\n'まとめ
Prompt Flowの基本的な使い方から評価→デプロイまでの一連の流れをご紹介しました。
プロンプトエンジニアリングに必要な機能が充実しており、効率的な開発サイクルがPrompt Flow内で完結できる強力なツールであることが伝われば幸いです。
今回はご紹介できませんでしたが、独自のデータソースを定義してRAGのフローを構築することも可能です。
幣部が以前参加した「AI Challenge Day」の参加レポート記事に、Prompt FlowでRAGを構築する場面が出てくるのでそちらも良ければご参照ください。
その他、評価メトリクスやノードとして接続できるツール等、利用できる機能は沢山あるので、プロジェクトの特性に合わせてぜひPrompt Flowを活用してみてください!
当社では、「Azure OpenAI Service の導入ソリューション」や「ナレッジマイニングPoCサービス」をはじめとして、お客様の業務に効果的にAIシステムを導入、活用するための支援やサービスを提供しています。
AIを用いた課題解決に興味をお持ちいただけましたら、ぜひ弊社へお声掛けいただけますと幸いです。
 (←参考になった場合はハートマークを押して評価お願いします)
(←参考になった場合はハートマークを押して評価お願いします)