1. はじめに
こんにちは。NewITソリューション部のエンジニアの今井です。
DBを用いた開発や運用をするにあたり、思うような性能が出ず困ってしまった経験はありませんでしょうか?
今回は、SQL ServerのSELECT文の応答が遅い問題を解決した際に学んだSQL Serverの仕組みなどについて記載したいと思います。
2. 直面した性能問題について
今回対応した性能問題の概要は以下の通りです。
-
テーブル構成
テーブルA:約2000万件
テーブルB:約1300万件 -
問題のクエリ
SELECT * FROM [テーブルA]
INNER JOIN [テーブルB] ON [結合条件]
WHERE [取得条件] -
取得件数
数件~6000件(取得条件次第) -
発生していた問題
同程度の件数のSELECTにかかる時間が、取得条件次第で変わる
5000件の取得に条件次第で、速いときは5秒、遅いときは25秒程度かかる状態 -
原因調査の中で判明した速いときと遅いときの違い
遅い場合の物理読み取り(特に先行読み取り)が、速い場合の7~8倍発生している
論理読み取り量・物理読み取り量は以下のクエリで取得できます。
SET STATISTICS IO ON;
[調査対象のクエリ]
SET STATISTICS IO OFF;
以降の章で論理読み取りや物理読み取りとは何なのか、どのようにこの性能問題を解決したかを記載していきます。
3. SQL Serverのデータ読み取りの仕組み
まず、DB内のデータの持ち方についてです。
テーブルに保存されたデータはデータファイルに格納されています。
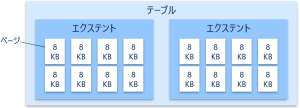
このデータファイルは論理的にページとエクステントという単位に区切って使用されます。
ページ:1ページのサイズは8KB。データ参照や更新の最小単位として扱われる
エクステント:8個のページで構成される。テーブルにページを割り当てるときはエクステント単位で割り当てられる
論理的にこのようなイメージでデータが保持されています↓
次に、SQL Serverがデータを読み取るときの仕組みについてです。
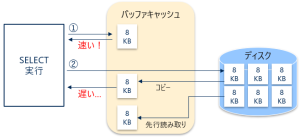
上に記載した通りI/Oの最小単位はページであり、データ読み取りの際はページ単位で読み取りを行います。
データ読み取りの流れは以下の通りです。
①バッファキャッシュからデータを読み取る(論理読み取り)
②バッファキャッシュにデータがない場合はディスクから読み取る(物理読み取り)
物理読み取り時に、バッファキャッシュ上にデータがページ単位でコピーされる
論理読み取りの方が物理読み取りより速いため、
論理読み取りの割合(キャッシュヒット率)を上げることがクエリの応答速度を上げるうえで大事になります。
また、SQL Serverはクエリ実行プランから必要になりそうなページを予測し、予めバッファキャッシュにページを読み込むことも行っています。
これは先行読み取りと呼ばれます。
4. SQL Serverのデータ格納順について
データの読み取りがページ単位であることから、取得対象のデータが同一ページ内に格納されているほど、物理読み取りの回数を減らすことができると考えられます。
また、おそらくですが、下記MSドキュメントの「先行読み取り」の説明に、
「1 つのファイルから連続するページを最大 64 ページ (512 KB) まで読み取ることができます。」と記載があることから、
取得対象のデータができるだけ連続したページ・近いページにある方が、先行読み取りがより有効に働くようになると考えられます。(個人の見解です。)
では、データの格納順がどのように決まるかですが、結論から述べるとINDEXで決まります。
INDEXには以下2種類あります。
クラスター化INDEX:テーブルのデータ格納順が決まる
リーフノードにテーブルのデータを保持する
テーブルに1個しか持てない
非クラスター化INDEX:リーフノードにデータ行へのポインタを保持する
テーブルに複数持てる

上記から、クラスター化INDEXを張る際には、取得条件で指定される可能性の高いカラム(特に大量件数の取得時に取得条件として指定することが多いカラム)でクラスター化INDEXを張り、同時に取得される可能性の高いデータを近くのページに格納しておくのがいいのではないかと考えます。
ただし、データの登録・更新時に走るインデックスの更新のオーバーヘッドや、データが主キー順でなくなることの影響については考慮が必要です。
ちなみに、テーブルに主キー制約を張る際に、当該テーブルにクラスター化INDEXがまだ張られていない場合は、主キー制約で指定したカラムでクラスター化INDEXが構築されます。
5. 実施した性能改善策とその効果
ここまでの話を踏まえて、今回発生した性能問題「SELECTにかかる時間が、取得条件次第で変わる」をどのように解決したかですが、
これまで自動採番の主キーに張られていたクラスター化INDEXを、「大量取得時に指定されることが多いカラム + 主キー」の複合カラムでクラスター化INDEXにしました。
その効果は以下の通りです。
Before
| 取得条件 | 取得件数 | 物理読み取り量 (先行読み取り量含む) |
クエリの応答時間 |
| 応答が速い取得条件 | 5,757件 | 7,817 | 5秒 |
| 応答が遅い取得条件 | 5,724件 | 54,925 | 23秒 |
After
| 取得条件 | 取得件数 | 物理読み取り量 (先行読み取り量含む) |
クエリの応答時間 |
| 応答が速い取得条件 | 5,757件 | 2,895 | 4秒 |
| 応答が遅い取得条件 | 5,724件 | 14,045 | 8秒 |
応答速度に差があったクエリをかなり改善することができました。
ついでに元々速かった方も改善されました。
6. まとめ
今回は、性能問題に対応した話・その中で身に着けた考え方について記載いたしました。
DBを設計する際には、業務運用上どのように使われるかを考慮した上で、データの構造だけでなく、データ格納順も考えた方がいいということを学ぶことができました。
超大量のデータから大量データを取得する場合など、今回の話が役に立つケースは限られるかもしれませんが、どこかでDB設計や性能改善対応の一助になれば幸いです。
弊社にご興味をお持ちいただけましたらお気軽にお問い合わせいただけると幸いです。
 (この記事が参考になった人の数:3)
(この記事が参考になった人の数:3)