この記事は更新から24ヶ月以上経過しているため、最新の情報を別途確認することを推奨いたします。
こんにちは。NewIT部のフルスタックエンジニアの天谷(あまがい)です。
本記事では、Azure AI Searchを理解し使用できるようになるための取っ掛かりとなる情報を提供いたします。
この記事はこのような方向けです
本記事は、以下に該当する方を対象として想定し作成しています。
- RDB(リレーショナルデータベース)のことならそれなりに知っている、または扱ったことがある。
- Azure AI Searchのことがよく分からない。
※インデクサーやスキルセットといった要素について知らない、あるいは役割が分からないというレベル感を想定。
MS公式の説明をいきなり読み進めるのはハードルが高い!と感じられる方々にファーストステップとしてお読みいただければ幸いです。
そもそも「Azure AI Search」って何?
詳細はMS公式の説明の通りですが、あえて平たく説明すると、 「取り込ませたデータをAI等で解析させ、その結果を柔軟かつ短時間で検索することを可能にするためのサービス」 です。
取り込ませることが可能なデータはPDFやOffice系ファイル等々多岐に渡りますが、そのような元データをどのように取り込ませるかという機構の部分も Azure AI Search に担わせることが可能です。
データを取り込ませる際にできる解析として、例えば以下のようなものがあります。
- 翻訳
文章を取り込んだ場合、その文章を任意の言語に翻訳させることができます。 - エンティティ抽出
文章や画像に含まれる人物や地名等の情報を抽出させることができます。 - 画像認識(OCR含む)
PDFやPowerPoint上に載っているものを含め、画像上の要素や画像上の文字を抽出させることができます。
これらのような解析をパラメーター設定だけで呼び出して使うことができてしまうという点も、Azure AI Searchの強みの1つです。
標準機能に収まらない独自性の強い解析を行いたい場合であっても、「カスタムスキル」を独自実装して組み入れることが可能となっています。
Azure AI Searchの構成要素をRDB利用システムに例えて理解しよう
例えば、RDBを利用している以下のようなシステムがあるとします。
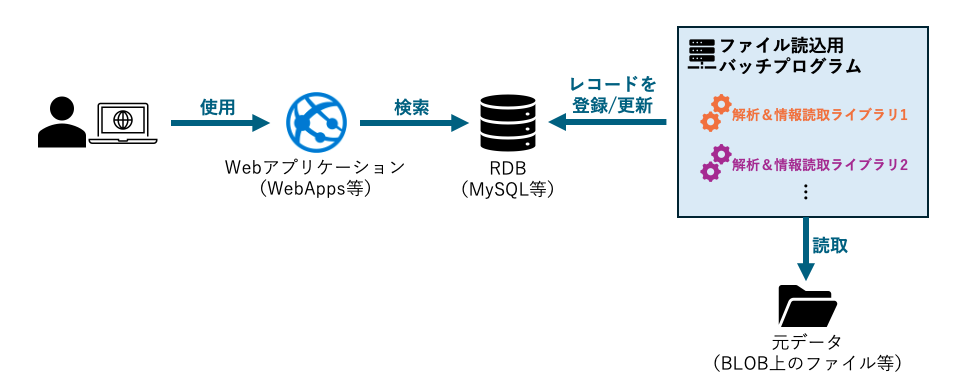
これは、「バッチプログラムを使って元データの内容を抽出・解析し、それをRDBに収めてWebから検索可能にする。」というシステムを意図したものです。
そのバッチプログラムが何かしらのライブラリ(C#で言うならNuGetパッケージ、Pythonで言うならpipで取得するようなパッケージ)を活用する形で作られている、というイメージです。
このシステムのデータ取り扱い部分をそっくりAzure AI Searchに置き換えてみると、以下のようになります。
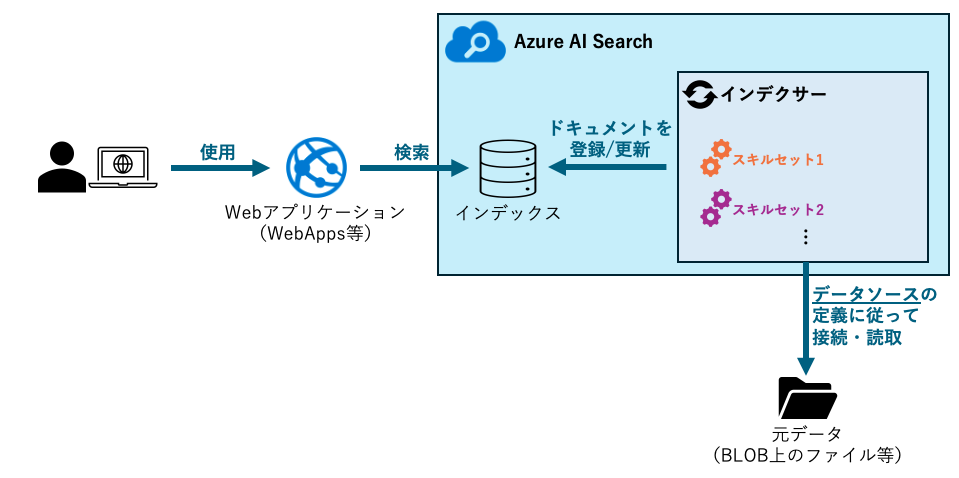
RDBを利用する場合と比べてどこがどう置き換わるかを纏めると、以下のような具合になります。
| RDB利用システム | Azure AI Search 利用システム |
|---|---|
| テーブル | インデックス |
| テーブル上のレコード (データ構造は表形式) |
インデックス上のドキュメント (データ構造はJSON形式) |
| ファイル読込用バッチプログラム | インデクサー |
| 解析&情報読取用ライブラリ | スキルセット |
RDB利用システムを構築する場合に上記の各要素を揃えるのと同様に、Azure AI Searchを使用する場合にも各要素を揃えていく形となります。
これらに加え、Azure AI Searchでは、元となるデータをどこから取って来るか等の定義情報である「データソース」を用意します。
Azure AI Searchをどう使い始めれば良い?
手順の全体像
Azure AI Searchを使い始めるためには、先述の各要素を用意し繋げていくわけですが、その手順もRDB利用システムと同等に考えることができます。
RDB利用システムを構築していく場合、全体の設計や構想がすでにある状況であれば、まずは以下のいずれかから作り始めることになるかと思います。
- RDBおよびテーブル
- 解析&情報読取ライブラリ
- 元データ置き場(BLOB等)
これらを作成してから、これらを繋げるように「ファイル読込用バッチプログラム」を組んで接続・疎通させていく、という流れとなります。
この流れはAzure AI Searchでも同等です。 つまり、各要素の容れ物となるAzure AI Searchのリソースそのものを作成した上で、その中に
- インデックス
- スキルセット
- 元データ置き場(BLOB等)およびデータソース
のそれぞれを作成し(3つのどれから作ってもOK)、その後で「インデクサー」を作って接続・疎通させていく、という流れとなります。
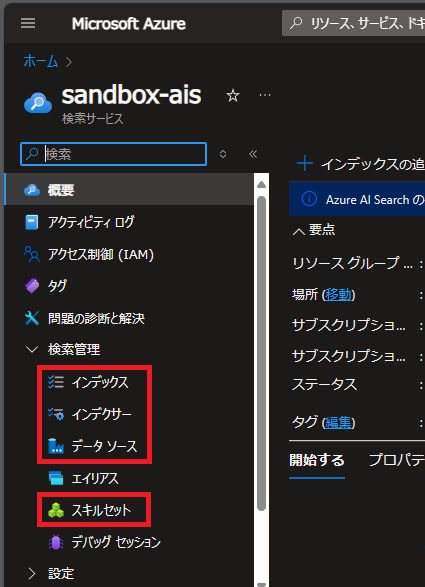
本記事では上から順に作っていくものとします。これらは、Azure AI Searchのリソースのメニュー上で、「検索管理」の配下に以下のように並んでいます。
具体的なイメージを掴みやすくするため、以下のようなシステムのバックエンドを組むものと仮定して解説していきます。
- AzureのBLOBストレージ上に置かれたテキストファイルを1時間に1回の周期で監視し、ファイルの新規設置・更新・削除を検知させる。
- 新規設置または更新されたテキストファイルについては、その内容を読み取り、テキストを英訳した上で、原文と共にインデックスに投入する(=検索・取得ができるようにする)。
- 削除されたテキストファイルについては、インデックス上から削除する。
1. インデックスの作成
Azure AI Searchリソースのメニューの「検索管理」配下にある「インデックス」をクリックし、画面上部に表示される「インデックスの追加」をクリックすると、以下のような画面が表示されます。
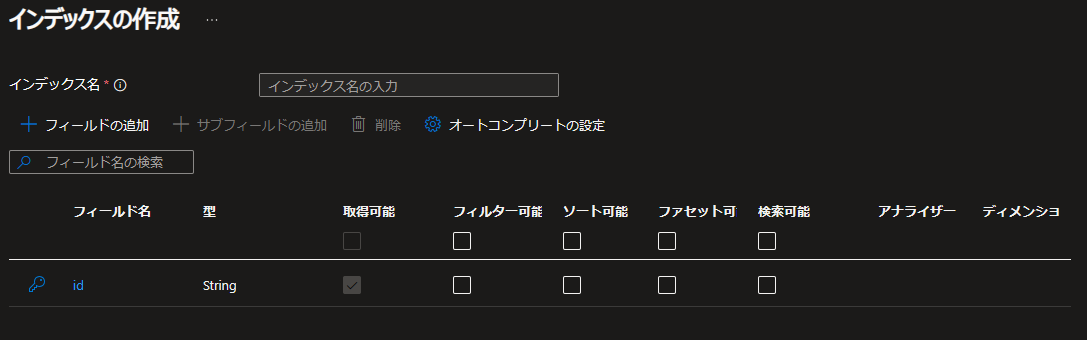
DBでテーブルを作る際のカラム定義とだいぶ雰囲気が近いかと思います。「フィールド」は、RDBで言うところのカラムに相当します。
ここに、「ファイル名を格納するフィールド」、「テキストの原文を入れるフィールド」と、「テキストの英訳文を入れるフィールド」を追加します。
それぞれのフィールド名は、「file_name」「text_original」「text_en」とします。
インデックス名に「sandbox-index」と入力した上でフィールドを以下のように設定し、「作成」をクリックします。

フィールド属性(フィルター可能、ソート可能、etc…)の詳細は、MS公式のドキュメントに記載の通りとなります。
2. スキルセットの作成
Azure AI Searchリソースのメニューの「検索管理」配下にある「スキルセット」をクリックしてから、画面上部に表示される「スキルセットを追加」をクリックすると、以下のような画面が表示されます。
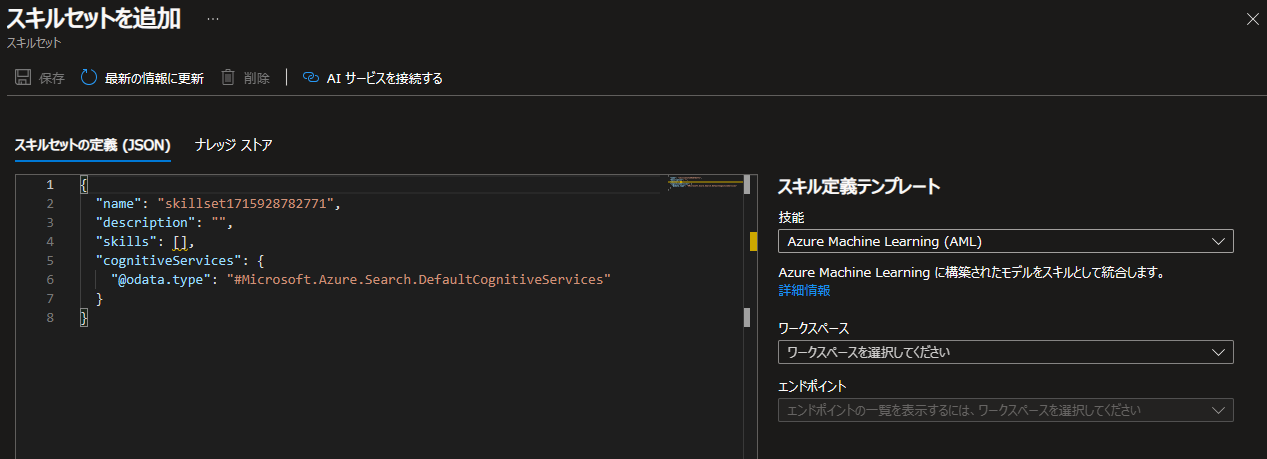
Azure AI Searchでは、(カスタムスキルと呼ばれる任意の解析ロジックを作り込む場合は例外となりますが、)プログラムを書くのではなく、JSONを記載する方式でスキルセットを作成します。
今回の例では翻訳用のスキルを使用したいので、画面右側の「スキル定義テンプレート」上の「技能」のプルダウンの中から「翻訳スキル」を選択します。すると、その直下に翻訳スキルを使用するためのJSONのテンプレートが呼び出されます。
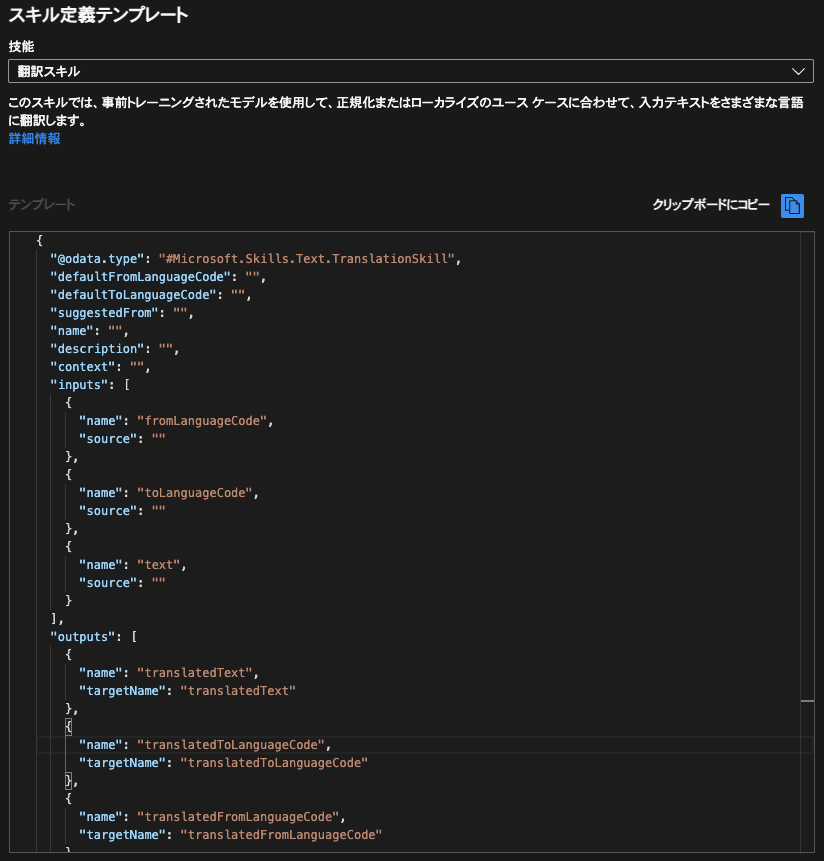
このテンプレートを丸ごと左側の”skills”の括弧内にコピーして、適切に書き換えればOKです。ついでに、スキルの名前(name)と説明(description)も書き直してしまうと良いでしょう。
今回は、以下のようにスキルセットを定義し、保存します。
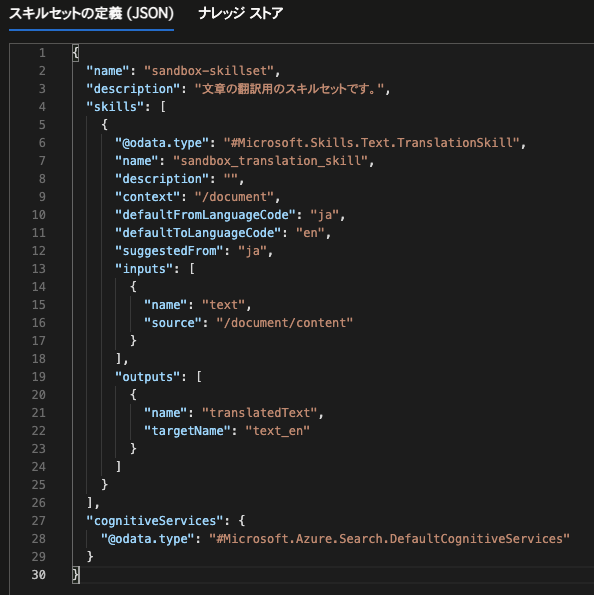
スキルの定義上の各パラメーターの意味はMS公式の翻訳スキルの解説に記載の通りです。
この定義の場合、
「ファイルの本文(/document/content)を入力として、それを日本語(ja)から英語(en)へ翻訳し、その出力を項目”text_en”として返す。」
という意味となります。
3. 元データ置き場(BLOB等)とデータソースの作成
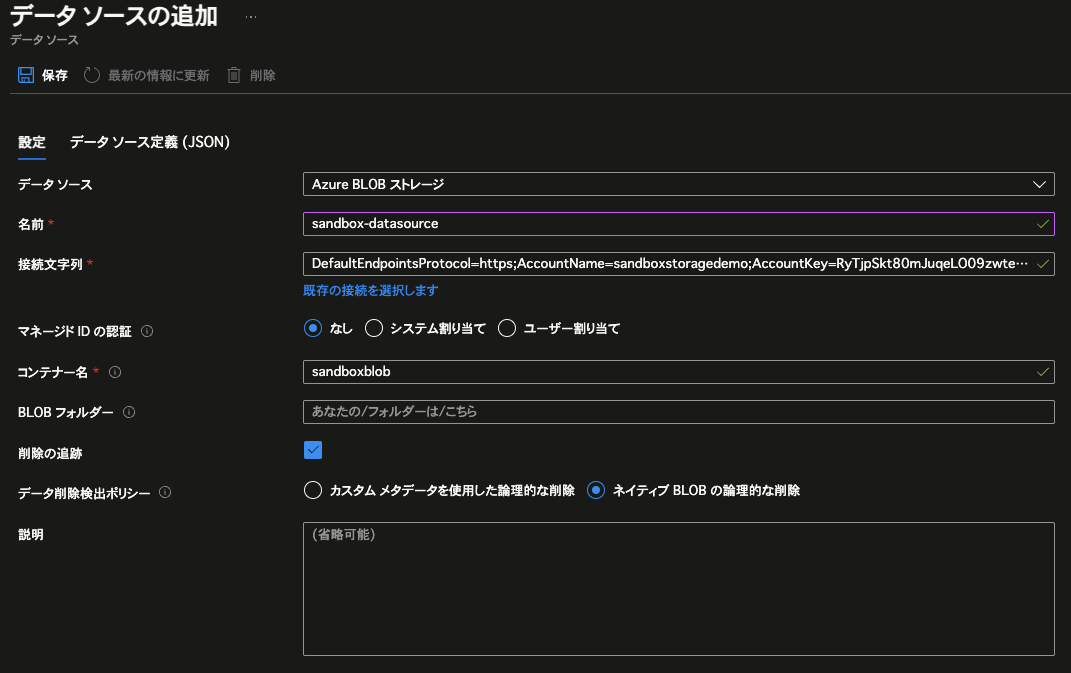
まずは任意のAzureストレージとコンテナー(BLOB)を作成します。今回は、「sandboxstoragedemo」という名前のAzureストレージ上に「sandboxblob」という名前のコンテナーを作成しました。
その上で、データソースの作成に入ります。Azure AI Searchリソースのメニューの「検索管理」配下にある「データソース」をクリックしてから、画面上部に表示される「データソースの追加」をクリックすると、以下の画面が表示されます。
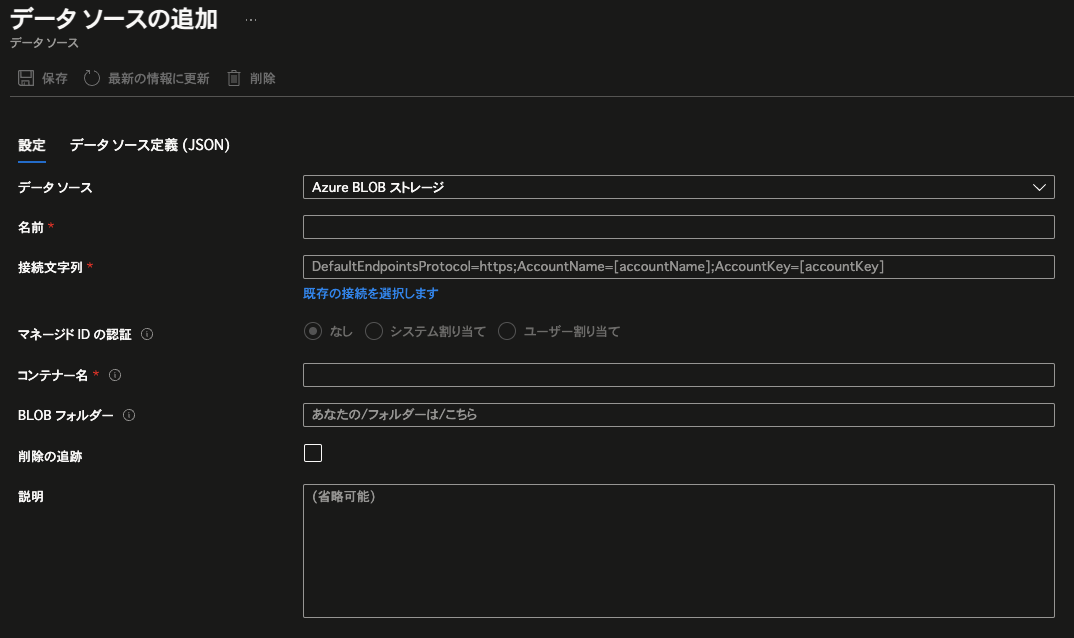
まずは疎通させて動かそうという観点で、以下の通りに設定し、「保存」をクリックします。
尚、接続文字列については、画面上にある「既存の接続を選択します」のリンクから辿ると簡単に入力することができます。
4. インデクサーの作成
最後に、これまで作ってきた各要素を繋げるようにインデクサーを作成します。
Azure AI Searchリソースのメニューの「検索管理」配下にある「インデクサー」をクリックしてから、画面上部に表示される「インデクサーの追加」をクリックすると、以下の画面が表示されます。
追ってJSON側から細かいパラメーターを手入れしていくことが必要となりますが、まずは以下のように入力し、「保存」をクリックします。
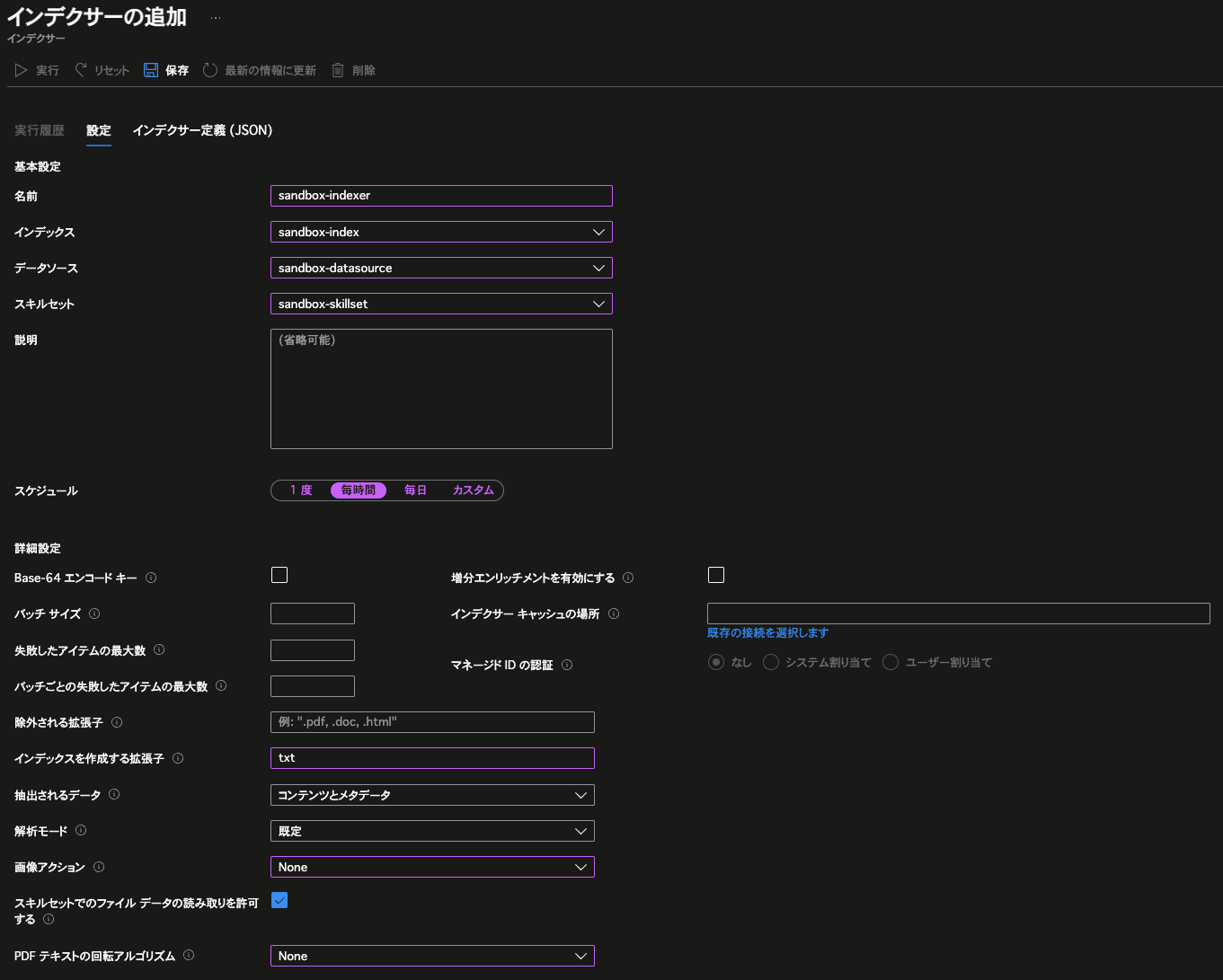
こうすることで、
「コンテナー”sandboxblob”の配下に置かれたtxtファイルのみを毎時解析する。」
という設定を持つインデクサーが出来上がります。
保存後、同画面上でタブ「インデクサー定義(JSON)」を開き、インデックス上のフィールドやスキルセットの入出力とのマッピングを行います。JSON上の「fieldMappings」と「outputFileMappings」を以下の通りに定義し、保存します。
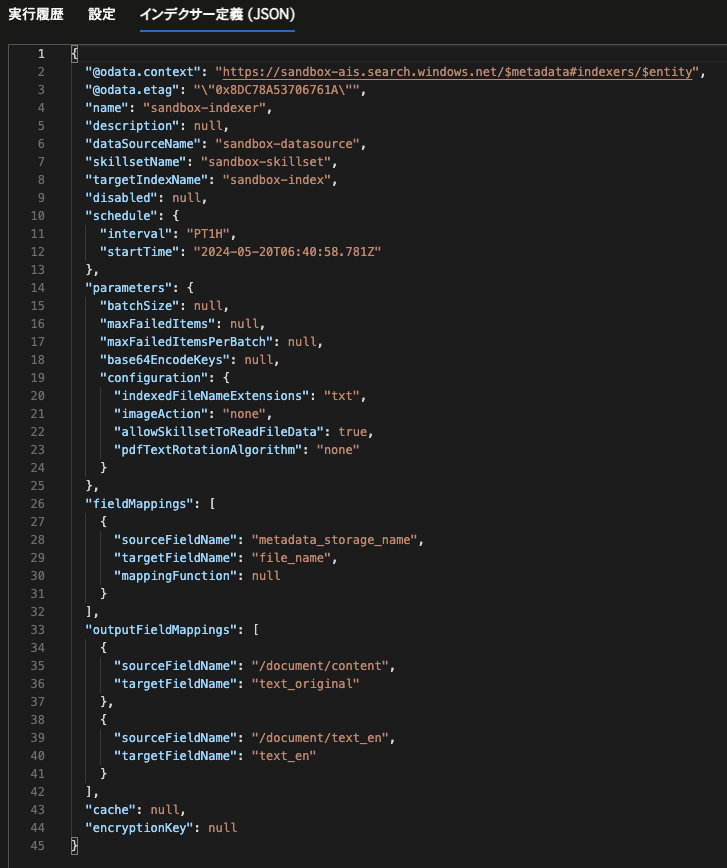
こうすることで、以下の通りのマッピングが実現します。
- 元データとなるファイルの名前(metadata_storage_name)がインデックス上のフィールド”file_name”にマッピングされる。
- ファイルの本文(/document/content)がインデックス上のフィールド”text_original”にマッピングされる。
- カスタムスキルで定義した出力(/document/text_en)がインデックス上のフィールド”text_en”にマッピングされる。
5. 疎通確認・動作検証
では、ここまでの手順で構築したAzure AI Searchを実際に動かしてみましょう。この手順通りに構築している場合、ファイルの読込・解析は、手順の中で用意したコンテナーに任意のテキストファイルを置くことで1時間以内に自動実行されます。
ここでは、青空文庫にある文学作品の序文が書き込まれたテキストファイル3つを用意し、読み込ませてみます。コンテナーにファイルをアップロードした後にインデクサーの定期実行を待っても問題ありませんが、インデクサーの画面上にある「実行」ボタンをクリックすることで即時実行させることも可能です。
同画面上では、以下のようにインデクサーの実行履歴を確認することも可能です。
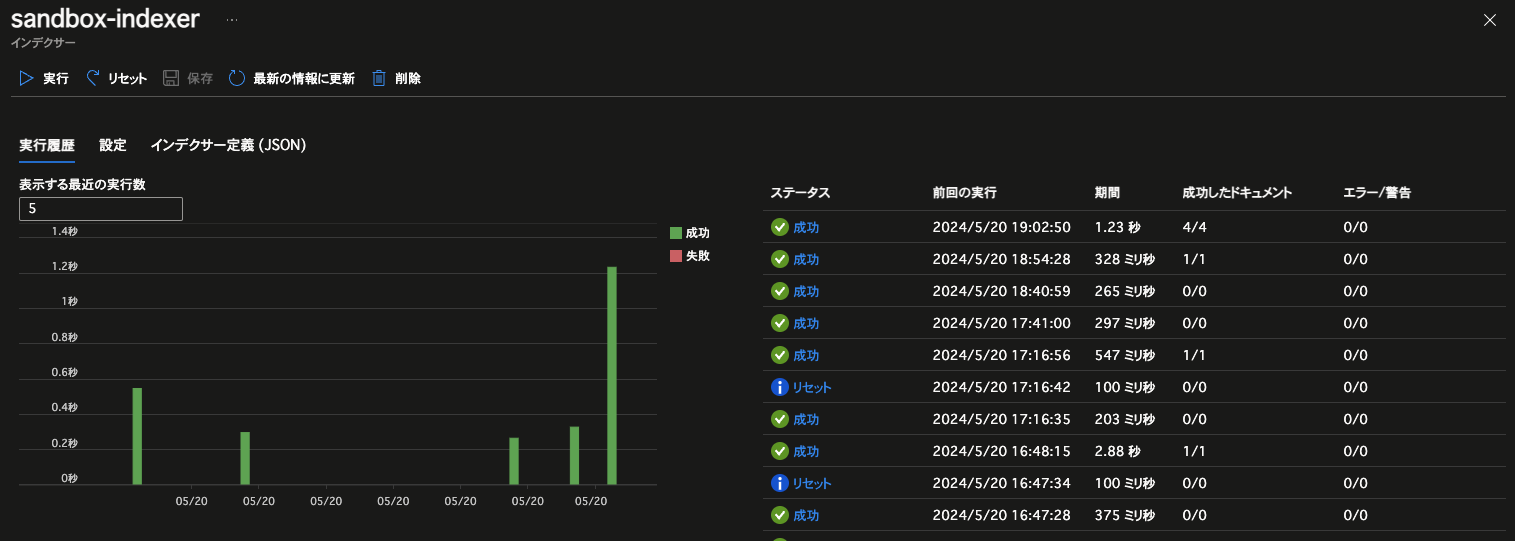
処理に成功したら、インデックス「sandbox-index」を開きましょう。
タブ「検索エクスプローラー」を開いてから検索欄が空欄のまま「検索」ボタンをクリックすると、インデクサーによって取り込まれた3つのドキュメントが英訳付きでヒットすることを確認できます。
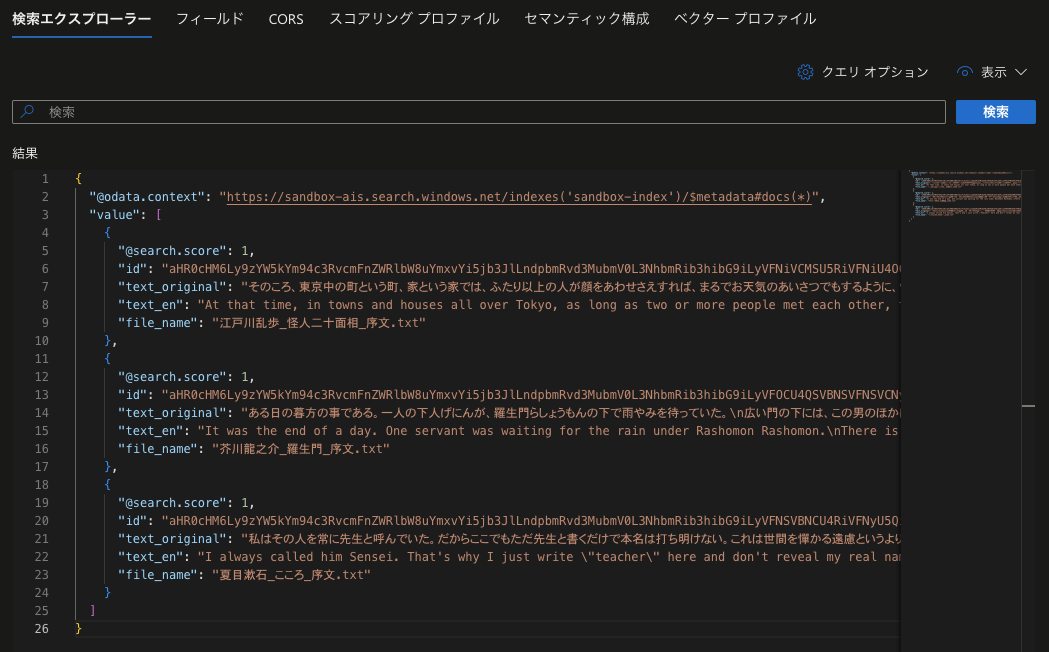
ドキュメントの検索はREST APIや各種言語向けのSDK経由でも可能なので、様々なプラットフォームから使用することができます。REST APIは度々バージョンアップされるので、使用する際は公式ドキュメントを確認することをお勧めします。
さいごに
本記事でご紹介したように、Azure AI Searchの構成はRDBを使ったシステムとの対比で理解していくことが可能であり、しかも、AIを用いた解析機能をスムーズに組み入れることが可能な作りとなっています。
とは言いつつも、ユーザーの様々なニーズを見据えた構築を実現していこうとする場合は、相応の工夫や独自拡張(カスタムスキルの作成等)が必要となってきます。そこはエンジニアの腕の見せ所です。
当社では、「Azure OpenAI Service の導入ソリューション」や「ナレッジマイニングPoCサービス」をはじめとして、お客様の業務に効果的にAIシステムを導入、活用するための支援やサービスを提供しています。
AIを用いた課題解決に興味をお持ちいただけましたら、ぜひ弊社へお声掛けいただけますと幸いです。
 (この記事が参考になった人の数:4)
(この記事が参考になった人の数:4)