この記事は更新から24ヶ月以上経過しているため、最新の情報を別途確認することを推奨いたします。
以前の記事でApp Serviceにおけるスケールイン/アウトの各項目の説明を行いました。
今回は予想されるアクセス増に対応する設定、急激なアクセス増に対する設定、ユーザー影響を限りなく抑えてスケールインする設定について紹介します。
以前の記事と合わせてご覧いただくとより理解がしやすいかと思います。
パターン①:予想されるアクセス増に対応する設定
この設定はメルマガによる告知や、xx時にオープン予定のサイトなど、アクセス増の時刻が予想される場合に行っておく設定となります。
アクセス増の時間がわかっている場合は、あらかじめインスタンスの数を増やしておきましょう。
設定としてはオートスケールではなく、時間帯とインスタンス数を指定することで、負荷に関係なく設定した期間のインスタンス台数が固定されます。
—
スケールモード:特定のインスタンス数にスケーリングする
インスタンス数:任意
スケジュール、タイムゾーン、開始日、終了日:指定の時間帯
設定内容:指定した期間において、インスタンス数をx台に固定する
—
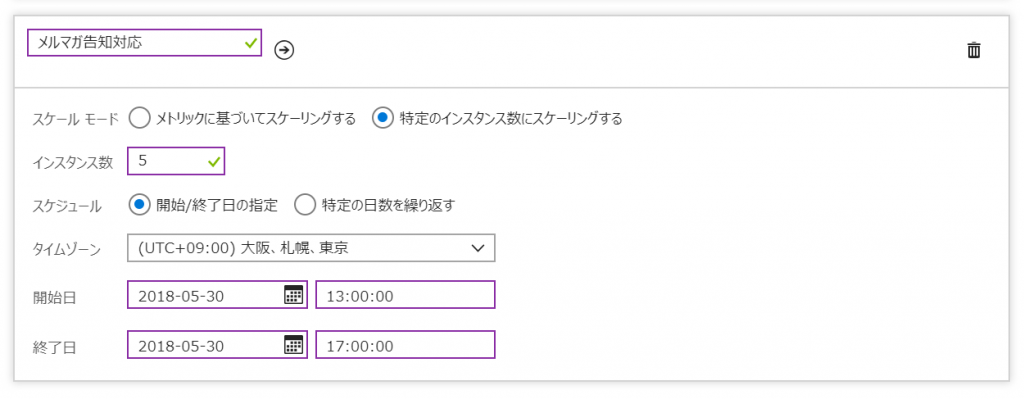
▲期間指定によるスケールルールの設定例
パターン②:急激なアクセス増に対する設定
この設定は、予測していない状態で発生する突発的なアクセス増に対応する設定です。
スケールイン/アウトの判定は1分毎に行われているため、この設定にすることで、急激なアクセスを察知して1分でスケールアウトが開始されます。
—
時間の集計:最終
メトリック名:CPU Percentage
時間グレインの統計:最大
演算子:次の値より大きい
しきい値:通常のCPU Percentageに+20%程度
期間:10
設定内容:直前の1分間の間に取得した5~15秒単位で集計しているCPU Percentageの値が1回でもしきい値を超えた場合Actionを実行する
—
パターン③:ユーザー影響を限りなく抑えてスケールインする設定
この設定は、アクセスがあまりなく、インスタンス性能を必要としない場合にインスタンス台数を減らす設定です。これによって夜間などに稼働インスタンスを抑えてコストの適正化が実現できます。また、この設定については以下Tipsの3つめもご参照ください。
—
時間の集計:平均
メトリック名:CPU Percentage
時間グレインの統計:平均
演算子:次の値より小さい
しきい値:通常のCPU Percentage
期間:60
設定内容:1分間の間に取得した5~15秒単位で集計しているCPU Percentageの値の平均値、更にその60分間分の平均値がしきい値より低い場合Actionを実行する
—
その他Tips
・スケールアウト開始からインスタンスがアクセスをさばけるようになるまでの時間
スケールアウトが開始してから追加されたインスタンスでアクセスを捌けるようになるまでには、追加分インスタンスの起動+アプリケーションの起動時間でどんなに早くても2-3分はかかってしまいます。ある程度予想されるアクセス増であれば、やはりパターン①の設定をしておく方が無難ではあります。
・アクセスがないのにCPU負荷が高騰する場合
App ServiceはAzureが提供する仮想インスタンス上で稼働しています。そのため、インスタンスに対するアップデートや、アンチマルウェアスキャンなどが発生すると、アクセスがないにも関わらずCPU負荷が上がる場合があります。
また、この影響はインスタンスサイズが低いほど大きく、あくまで弊社の実績ベースですが、S2以下だとその影響が顕著のようです。
・スケールインする際の削除されるインスタンス上のセッション
スケールインが実行される場合、まず削除されるインスタンスには新規アクセスで割り振られなくなり、その90秒後にインスタンスが削除されます。削除予定のインスタンスに割り振られているアクセスは90秒の間にページ遷移やセッション再接続が行われると新規インスタンスに割り振られます。
つまり、削除予定のインスタンスに割り振られたアクセスは、スケールインが動作してから90秒以上セッション再接続が発生しない場合、接続が切断されます。とはいえ、ページ更新によって再接続が可能なため、デフォルトのままである程度ユーザー影響は抑えられる設定となっています。
 (この記事が参考になった人の数:1)
(この記事が参考になった人の数:1)