はじめに
皆様こんにちは。NewITソリューション部です。
我々NewITソリューション部においては、最近は流行に倣いAzure Open AI Serviceを活用した引き合いを多く頂いているのですが、Azureのサービスを用いないAI系Webシステム開発の引き合いも頂いております。
本記事では、ブラウザに機械学習の結果をリアルタイムに表示するサンプルをご共有します。またサンプルに必要な技術要素のうち、リアルタイム配信、メモリ共有、および顔画像識別について解説します。
(※)本記事のサンプルをご利用される際には、本記事末尾のインターネット上で公開されている学習済みモデルのライセンスについての注意事項にお気をつけください。
環境と使用パッケージ
本記事で利用する環境を以下に示します。
- Python (3.8以上、本記事のサンプルコードは3.12.3で確認)
- FastAPI
- NumPy
- OpenCV
- Dlib
- Chroma DB
- PyTurboJPEG(libjpeg-turboのPythonラッパー)
構成
本記事では、複数のワーカープロセスを立ち上げ個別の画像処理タスクを実行させ、また共有メモリを介してプロセス間でデータを連携する仕組みを作ります。
また、FastAPIからブラウザに映像をリアルタイム配信する部分には、Motion JPEG over HTTPを用います。
全体を簡単に図示すると以下のようになります。
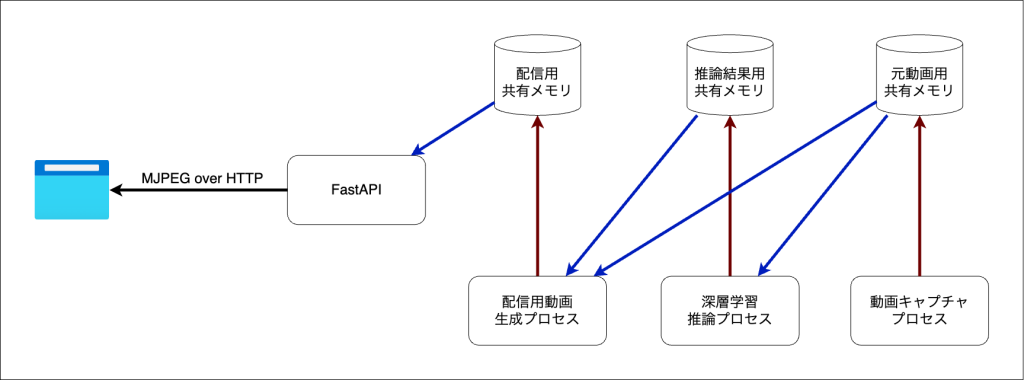
次の章では、各プロセス内で行う技術要素の解説を行います。
技術要素の解説
Motion JPEG over HTTPを用いたリアルタイム映像配信
FastAPIからブラウザに対してリアルタイムで映像の配信を行うには、multipart/x-mixed-replaceを用いたMotion JPEG over HTTPを用います。
multipart/x-mixed-replaceはHTTPレスポンスの一種で、サーバーからブラウザに対してデータをプッシュし、ブラウザ上の表示を更新させることができます。
今回はここでプッシュ配信するデータをJPEGとすることで、映像の配信を行います。
import cv2
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
app = FastAPI()
def generate_frames():
cap = cv2.VideoCapture(0)
ret, frame = cap.read()
while ret:
ret, buffer = cv2.imencode(".jpg", frame)
yield (b"--frame\r\n"
b"Content-Type: image/jpeg\r\n\r\n" + buffer.tobytes() + b"\r\n")
ret, frame = cap.read()
@app.get("/video")
def video():
return StreamingResponse(generate_frames(), media_type="multipart/x-mixed-replace; boundary=frame")SharedMemoryを用いた、プロセス間でのNumPy行列データ共有
Python 3.13では解消される想定ではありますが、PythonにはGlobal Interpreter Lockというものが存在しており、複数のスレッドを作成したとしても同時に実行可能なPythonスレッドは1つとなります。そのため重い処理を並列に実行したい場合は、マルチプロセスとして実行します。
マルチプロセスとして処理を並列に実行する場合、マルチスレッドとは異なりデータを同じメモリ空間で共有できない為、プロセス間でデータを共有する手段を何かしら考える必要があります。
Python 3.8以降のmultiprocessingパッケージ内にはSharedMemoryが実装されました。
この機能を用いることで、プロセス間で共有されるメモリ領域を作成することが可能です。
import multiprocessing
import numpy as np
from multiprocessing import shared_memory
def worker(shared_name):
existing_shm = shared_memory.SharedMemory(name=shared_name)
np_array = np.ndarray((480, 640, 3), dtype=np.uint8, buffer=existing_shm.buf)
np_array[:] = 128
existing_shm.close()
if __name__ == '__main__':
shm = shared_memory.SharedMemory(create=True, size=480*640*3)
np_array = np.ndarray((480, 640, 3), dtype=np.uint8, buffer=shm.buf)
np_array[:] = 0
p = multiprocessing.Process(target=worker, args=(shm.name,))
p.start()
p.join()
print(np_array)
shm.close()
shm.unlink()Dlibを用いた顔画像の埋め込みベクトル化、及びChroma DBを用いた顔画像の識別
Dlibを用いた顔の認識は、公式サンプルのFace Recognitionを参考にしています。 このサンプルにおいては、画像中の全ての顔を抽出し、それぞれの顔画像をベクトル化しています。 このベクトル化は、同一人物であればユークリッド距離が0.6以下となるように、また他人とは混同されないように学習された深層学習モデルを用いています。
出力されるベクトルはテキストの埋め込みベクトルと同様に扱うことができるため、今回はChroma DBを用いて高速な検索が出来るようにしています。 ただし、Chroma DBにはユークリッド距離で検索する方法が無いため、代わりにL2(ユークリッド距離の2乗)距離メトリックを用います。
(※)こちらのコードを動かすために必要となる各種学習済みモデルの注意点につきまして、本記事の末尾に補足として記載しております。併せてお読み頂けますと幸いです。
import secrets
import chromadb
import cv2
import dlib
import numpy as np
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="faces",
metadata={"hnsw:space": "l2"})
face_detector = dlib.get_frontal_face_detector()
pose_predictor = dlib.shape_predictor("<Pose Predictor Model>")
face_encoder = dlib.face_recognition_model_v1("<Face Encoder Model>")
cap = cv2.VideoCapture(0)
try:
flag, im = cap.read()
while flag:
faces = face_detector(im)
for i, face_location in enumerate(faces):
face_landmarks = pose_predictor(im, face_location)
face_chip = dlib.get_face_chip(im, face_landmarks)
encodings = face_encoder(face_chip)
encodings = list(encodings)
matched_faces = collection.query(
query_embeddings=[ encodings ],
n_results=1
)
id = matched_faces["ids"][0][0] if len(matched_faces["ids"][0]) > 0 else None
distance = matched_faces["distances"][0][0] if len(matched_faces["distances"][0]) > 0 else np.inf
if distance <= 0.36:
print(f"Matched: {id[:5]}, {distance}, {face_location}")
else:
print(f"New: {distance}, {face_location}")
collection.add(
embeddings=[ encodings ],
ids=[ secrets.token_urlsafe() ]
)
flag, im = cap.read()
finally:
cap.release()FastAPIを用いたリアルタイム動画解析アプリ
ここまでの解説内容を踏まえて、当初の目的であったリアルタイム動画解析アプリの実装を行うと、以下のようになります。
import secrets
import time
import chromadb
import cv2
import dlib
import numpy as np
from contextlib import asynccontextmanager
from logging import getLogger
from multiprocessing import Process
from multiprocessing.shared_memory import SharedMemory
from typing import Any
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic_settings import BaseSettings
from turbojpeg import TurboJPEG
logger = getLogger("fastapi-realtime-facedetection")
class Settings(BaseSettings):
FPS: float = 120.0
CV2_CAPTURE_INDEX: int|str = 0
POSE_PREDICTOR_MODEL_PATH: str = "<Your pose predictor model path>"
FACE_ENCODER_MOTEL_PATH: str = "<Your face encoder model path>"
FACE_THRESHOLD: float = 0.36
settings = Settings()
def _capture_worker(settings: Settings,
output_shm_name: str,
video_width: int,
video_height: int,
video_fps: float):
logger.info("_capture_worker: start(capture_index=%s, output_shm_name=%s, video_width=%d, video_height=%d)", settings.CV2_CAPTURE_INDEX, output_shm_name, video_width, video_height)
cap = shm = None
try:
im_shape = (video_height, video_width, 3)
shm = SharedMemory(name=output_shm_name)
buffer = np.ndarray(im_shape, dtype=np.uint8, buffer=shm.buf)
while True:
cap = cv2.VideoCapture(settings.CV2_CAPTURE_INDEX)
flag, _ = cap.read(buffer)
while flag:
flag, _ = cap.read(buffer)
time.sleep(1/video_fps)
cap.release()
cap = None
finally:
logger.info("_capture_worker: finally")
if cap is not None:
cap.release()
if shm is not None:
shm.close()
def _facedetect_worker(settings: Settings,
capture_shm_name: str,
output_shm_name: str,
video_width: int,
video_height: int):
logger.info("_facedetect_worker: start(shape_predictor=%d, face_recognition=%d, capture_shm_name=%s, output_shm_name=%s, video_width=%d, video_height=%d)", settings.POSE_PREDICTOR_MODEL_PATH, settings.FACE_ENCODER_MOTEL_PATH, capture_shm_name, output_shm_name, video_width, video_height)
shm_in = shm_out = None
try:
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="faces",
metadata={"hnsw:space": "l2"})
face_detector = dlib.get_frontal_face_detector()
pose_predictor = dlib.shape_predictor(settings.POSE_PREDICTOR_MODEL_PATH)
face_encoder = dlib.face_recognition_model_v1(settings.FACE_ENCODER_MOTEL_PATH)
face_threshold = settings.FACE_THRESHOLD
shm_in = SharedMemory(name=capture_shm_name)
shm_out = SharedMemory(name=output_shm_name)
input_im = np.ndarray((video_height, video_width, 3), dtype=np.uint8, buffer=shm_in.buf)
output_im = np.ndarray((video_height, video_width, 3), dtype=np.uint8, buffer=shm_out.buf)
buffer_output_im = np.zeros_like(output_im)
flag = True
while flag:
im = input_im.copy()
output_im[:] = buffer_output_im
buffer_output_im[:] = 0
faces = face_detector(im)
for i, face_location in enumerate(faces):
logger.debug("%d: %s", i, face_location)
face_landmarks = pose_predictor(im, face_location)
face_chip = dlib.get_face_chip(im, face_landmarks)
encodings = face_encoder.compute_face_descriptor(face_chip)
encodings = list(encodings)
matched_faces = collection.query(
query_embeddings=[ encodings ],
n_results=1
)
distance = matched_faces["distances"][0][0] if len(matched_faces["distances"][0]) > 0 else np.inf
id = matched_faces["ids"][0][0] if len(matched_faces["ids"][0]) > 0 else None
logger.debug("- %s: %f", id, distance)
left = face_location.left()
top = face_location.top()
width = face_location.width()
height = face_location.height()
if distance <= face_threshold:
cv2.rectangle(buffer_output_im,
(left, top),
(left+min(130, width), top+min(30, height)),
(0, 255, 0),
cv2.FILLED)
cv2.putText(buffer_output_im, id[:4], (left+10, top+25),
cv2.FONT_HERSHEY_PLAIN, 2.0,
(255, 255, 255), 1, cv2.LINE_AA)
cv2.rectangle(buffer_output_im,
(left, top),
(face_location.right(), face_location.bottom()),
(0, 255, 0),
5)
else:
cv2.rectangle(buffer_output_im,
(left, top),
(left+min(130, width), top+min(30, height)),
(0, 0, 255),
cv2.FILLED)
cv2.putText(buffer_output_im, "NEW", (left+10, top+25),
cv2.FONT_HERSHEY_PLAIN, 2.0,
(255, 255, 255), 1, cv2.LINE_AA)
cv2.rectangle(buffer_output_im,
(left, top),
(face_location.right(), face_location.bottom()),
(0, 0, 255),
5)
collection.add(
embeddings=[ encodings ],
ids=[ secrets.token_urlsafe() ]
)
finally:
logger.info("_facedetect_worker: finally")
if shm_in is not None:
shm_in.close()
if shm_out is not None:
shm_out.close()
def _stream_worker(settings: Settings,
capture_shm_name: str,
facedetect_shm_name: str,
output_shm_name: str,
video_width: int,
video_height: int):
logger.info("_stream_worker: start(capture_shm_name=%s, facedetect_shm_name=%s, output_shm_name=%s, video_width=%d, video_height=%d)", capture_shm_name, facedetect_shm_name, output_shm_name, video_width, video_height)
shm_in = shm_out = None
try:
shm_capture = SharedMemory(name=capture_shm_name)
shm_facedetect = SharedMemory(name=facedetect_shm_name)
shm_out = SharedMemory(name=output_shm_name)
capture_im = np.ndarray((video_height, video_width, 3), dtype=np.uint8, buffer=shm_capture.buf)
facedetect_im = np.ndarray((video_height, video_width, 3), dtype=np.uint8, buffer=shm_facedetect.buf)
output_im = np.ndarray((video_height, video_width, 3), dtype=np.uint8, buffer=shm_out.buf)
buffer_im = np.zeros_like(output_im)
output_im[:] = buffer_im
fps = settings.FPS
while True:
start = time.time()
buffer_im[:] = cv2.addWeighted(capture_im, 0.4, facedetect_im, 0.6, 0)
output_im[:] = buffer_im
end = time.time()
delay = 1/fps - (end - start)
if delay > 0:
time.sleep(delay)
finally:
logger.info("_stream_worker: finally")
if shm_in is not None:
shm_in.close()
if shm_out is not None:
shm_out.close()
class Worker:
def __init__(self):
cap = cv2.VideoCapture(settings.CV2_CAPTURE_INDEX)
self.video_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.video_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.video_fps = float(cap.get(cv2.CAP_PROP_FPS))
self.video_size = self.video_height * self.video_width * 3
print(f"Video Resoluton: {self.video_width} x {self.video_height} : {self.video_size}")
cap.release()
self.capture_shm_name = "capture"
self.facedetect_shm_name = "facedetect"
self.stream_shm_name = "stream"
self.shms = [
SharedMemory(create=True,
size=self.video_size,
name=name)
for name in [self.capture_shm_name, self.facedetect_shm_name, self.stream_shm_name]
]
self.processes = []
def start(self):
self.processes.append(Process(target=_capture_worker,
args=(settings,
self.capture_shm_name,
self.video_width,
self.video_height,
self.video_fps)))
self.processes.append(Process(target=_facedetect_worker,
args=(settings,
self.capture_shm_name,
self.facedetect_shm_name,
self.video_width,
self.video_height)))
self.processes.append(Process(target=_stream_worker,
args=(settings,
self.capture_shm_name,
self.facedetect_shm_name,
self.stream_shm_name,
self.video_width,
self.video_height)))
for process in self.processes:
process.start()
def terminate(self):
for process in self.processes:
process.terminate()
process.join()
for shm in self.shms:
shm.close()
shm.unlink()
@asynccontextmanager
async def lifespan(app: FastAPI):
worker = Worker()
worker.start()
yield
worker.terminate()
app = FastAPI(lifespan=lifespan)
def _mjpeg_stream(target_shm_name: str):
jpeg = TurboJPEG()
shm = SharedMemory(name=target_shm_name)
im = np.ndarray((720, 1280, 3), dtype=np.uint8, buffer=shm.buf)
fps = settings.FPS
while True:
start = time.time()
data = jpeg.encode(im, quality=95)
yield (b"--frame\r\n"
b"Content-Type: image/jpeg\r\n\r\n" + data + b"\r\n")
end = time.time()
delay = 1/fps - (end - start)
if delay > 0:
time.sleep(delay)
@app.get("/camera")
async def camera() -> Any:
return StreamingResponse(_mjpeg_stream("stream"),
media_type="multipart/x-mixed-replace; boundary=frame")まとめ
いかがでしたでしょうか?比較的に簡単にブラウザに対してリアルタイムな動画配信、および動画解析が行えていたかと思います。
我々NewITソリューション部においては、このようなAI機能をWebシステム化するご相談も承っておりますので、ご興味をお持ちいただけましたらお気軽にお問い合わせください。
補足
Dlibには教育ドキュメント用に公式が配布している学習済みモデルがあり、GitHub上には以下のように記載されております。
原文:
They are provided as part of the dlib example programs, which are intended to be educational documents that explain how to use various parts of the dlib library. As far as I am concerned, anyone can do whatever they want with these model files as I’ve released them into the public domain.DeepL:
これらはdlibサンプルプログラムの一部として提供されており、dlibライブラリの様々な部分の使い方を説明する教育的なドキュメントとして意図されています。私としては、これらのモデルファイルはパブリックドメインとして公開しているので、誰でも好きなように使うことができる。
一部モデルには商用利用禁止と明記されていますが、公式の顔識別サンプルコードで利用しているモデルに関しては特筆すべき記載がなく、一見すると上記の記述に従いパブリックドメインとして利用可能と判断できそうな状態です。
ただし、埋め込みモデルについては商用利用が禁止されているデータを含んだデータセットで学習されており、また顔ランドマークモデルはインターネットからダウンロードした画像としか記載されておりません。
このことからモデル自体の商用利用がライセンス違反となる恐れがあります。
本記事をご参考にされる際には、モデルのライセンス、また学習データセットのライセンスをご確認頂いた上でご利用いただきますようお願いいたします。
 (←参考になった場合はハートマークを押して評価お願いします)
(←参考になった場合はハートマークを押して評価お願いします)