この記事は更新から24ヶ月以上経過しているため、最新の情報を別途確認することを推奨いたします。
AI Challenge Dayとは
2024年の4月18・19日に神戸で開催された アスキー社 × マイクロソフト社主催のAIコンテストです。
AIのビジネス化を目論むマイクロソフトのパートナー10社が神戸でアイデアを競い合った生成AIの可能性を高め合う世紀のイベントです。
19日の様子はYoutubeでライブ配信していました。アーカイブがあるので是非ご覧になってください。
コンテストの内容を簡単に紹介
コンテストの内容
「日本の世界遺産」を紹介するアシスタントを開発しよう!

開催部門は以下の2つ。 『①FAQアシスタント』で質問に対して、いかに正解に近い応答を返せるか。 『②マルチモーダルアシスタント』で画像を添付された質問に対して、いかに正解に近い応答を返せるか。

コンテストのルール
- データセットのルール
-
- 提供されたデータセットはすべてRAG の検索対象とすること
- データは加工せずにシステムに取り込むこと
- アプリケーションのルール
-
- RAG アーキテクチャの構成は自由です ただし Web 検索は使用不可
- 回答に使用する生成AI モデルは自由です
- 開催部門あたり1 アプリケーションを開発する
- アプリケーションはコンテストの場で開発したものを評価する
- クラウドアプリケーションはAzure 上にホスティングする
- 採点方法
評価もLLMで実施!!

コンテストのデータセット
コンテストで用意されていたデータセットの一例を紹介します。一筋縄ではいかないがエンジニアの心をくすぐる内容でした。
- 単純テキストデータ
- ワードやエクセルファイル(ファイル内に文字を含む画像や建造物の写真あり)
- 紙媒体をスキャンしたPDFファイル
- 観光地・お土産などの写真
特に面白かったデータセットとして次のようなものがありました。
-
表の画像
表組みはRAGする上で問題となる場合が多いのに、画像? どのようにデータを取得するところが考えどころ
-
実在しない観光地
データセットから情報を取得しないと、絶対に回答できない架空の観光地が含まれていた。
-
画像を説明するCSVファイル
お土産などの写真の説明がCSVファイルにのみ記載されていた。 画像とどのように紐付ければいいのか?
次に今回構築した環境を説明します。
システム概要
Microsoftが公開している、RAGリファレンスアーキテクチャは以下のものです。
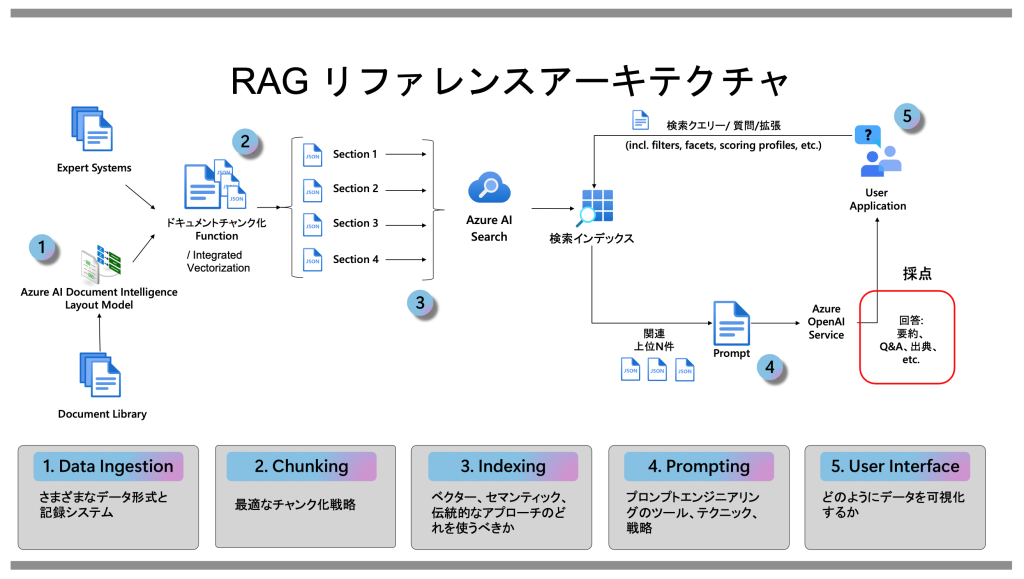
以下の点を考慮し、利用するサービスを決定していきました。
-
Data Ingestion、Chunking、Indexing
今回のデータセットには、プレーンテキスト、スキャンされたPDF、Office製品ドキュメント、画像など種類が多岐にわたっています。 「Azure AI Search」のインデクサーを用いれば、「Data Ingestion、Chunking、Indexing」を一気に処理できることを期待し、「Azure AI Search」を採用しました。
-
Prompting
プロンプトの修正のたびに評価が行えること、簡易UIを提供出来ることを考慮し「Azure AI Studio」の「PromptFlow」を採用しました。 また、「PromptFlow」で作成したフローからWeb・APIのDockerイメージを作成し、User Interfaceまでカバーできそうであるも大きな理由です。
-
User Interface
Webアプリケーションの動作環境として「Azure Container Apps」を採用しました。 「PromptFlow」で作成されるDockerイメージはAPIとしても動作するため、フロントエンドアプリケーションを別途作る場合「Azure Container Apps」は複数のコンテナの連携が容易であることも選定理由になりました。
実際に利用したサービスの構成は以下の通りです。
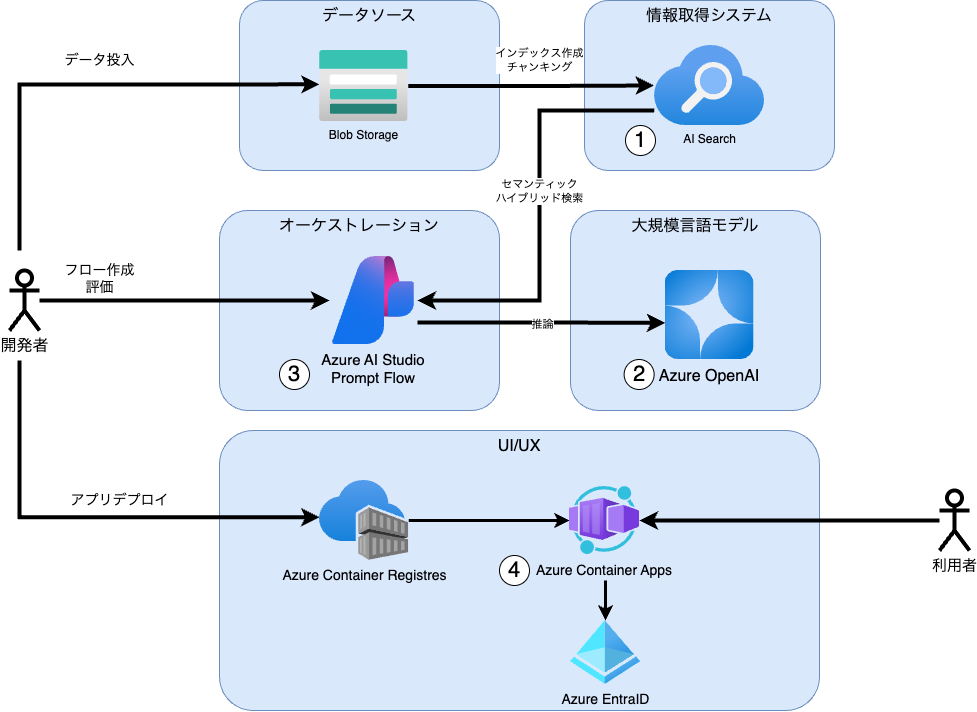
各サービスで工夫した点は、、、、
-
AI Search
レギュレーションで指定されたEmbeddingのモデルを「text-embedding-3-small」利用しました。 インデクサーにOCRスキルを適用し「紙からスキャンされたPDF」に対応しました。 チャンキングはQiitaの記事「Microsoft が Azure Cognitive Search による RAG システムの定量評価結果を公表」を元に設定しました。
-
Azure OpenAI
利用モデルは結果評価で利用するモデルをデプロイしました。現在、結果評価で利用するモデル全てをデプロイ可能なリージョンは存在しないため、Azure OpenAI Service モデル 公式ドキュメントを参考に、複数リージョンにAOAIサービスを構築しています。
-
Azure AI Studio
Azure AI Studio 組み込みの評価メトリックを設定し、フロー修正毎に評価を実施できる環境を作成しました。 Azure AI Studioで作成したフローは開発端末でDockerイメージ作成を並行して実施しました。
-
Azure Container Apps
Azure Container Appsの機能を利用し、Azure EntraID認証を追加しました。時間の都合でオリジナルのフロントエンドアプリの構築には至りませんでした。 普段、アプリケーション実行環境にはAzure Kubernetes Serviceを利用しているのですが、Azure Container AppsはKubernetesをうまくラップしていて使いやすい印象を受けました。小規模・PoCのアプリケーション実行環境で採用していきたいと思います。
やはり、Azure AI StudioのPromptFlowを採用したことは、今回のハッカソンを楽しめた最大の要因だったと思います。
- プロンプト・ロジック修正 → 評価 をその場で実施できる
- 思いついたアイディアをすぐに実現できるUI
- 開発端末(VSCode)でも同じUIで作業可能
- おまけでWebアプリがついてくる
実際のPromptFlowでの試行錯誤の一例を次に紹介します。
PromptFlowでの試行錯誤
初期の単純RAG
まず、AISearchをVectorStoreとした基本的なRAGのフローの作成をし、回答生成から評価までの流れを確立しました。
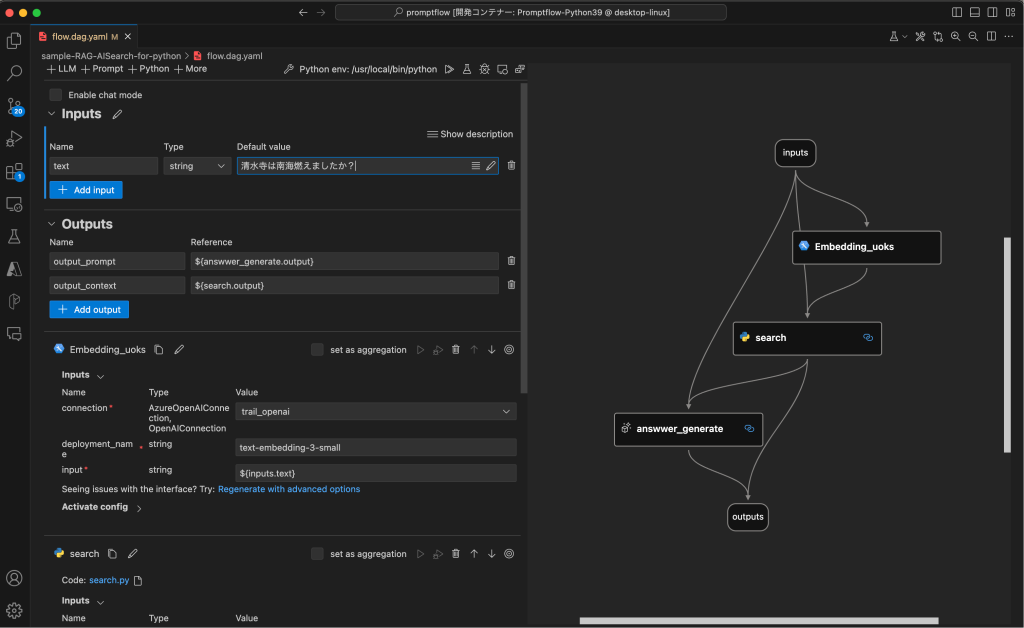
フローでは以下の点を考慮しました。
- Embeddings_uoks : 質問文(文字列)を採点で使用する「text-embedding-3-small」を用いてVector化。
- search : 質問文と質問文のVector値を用いて AzureAISearchにセマンティックハイブリッドサーチを実行。また、Dockerで動作させるためPromptFlow組み込みの検索パーツでは無く、Pythonで検索ロジックを作成
- answer_generate : 質問文とsearchの結果を用いて、gpt4で回答文を生成
RAGの精度を上げるための工夫
質問文に含まれる、検索には直接関係ない表示方法などの文言を取り除くことを検証しました。これを実施することで、意図した検索結果が得られるようになりました。
また、チャットの利便性を考慮し、会話履歴を検索文言に含めるようにしました。これを行うことで実際のチャットで自然なやりとりを行えるようになりました。
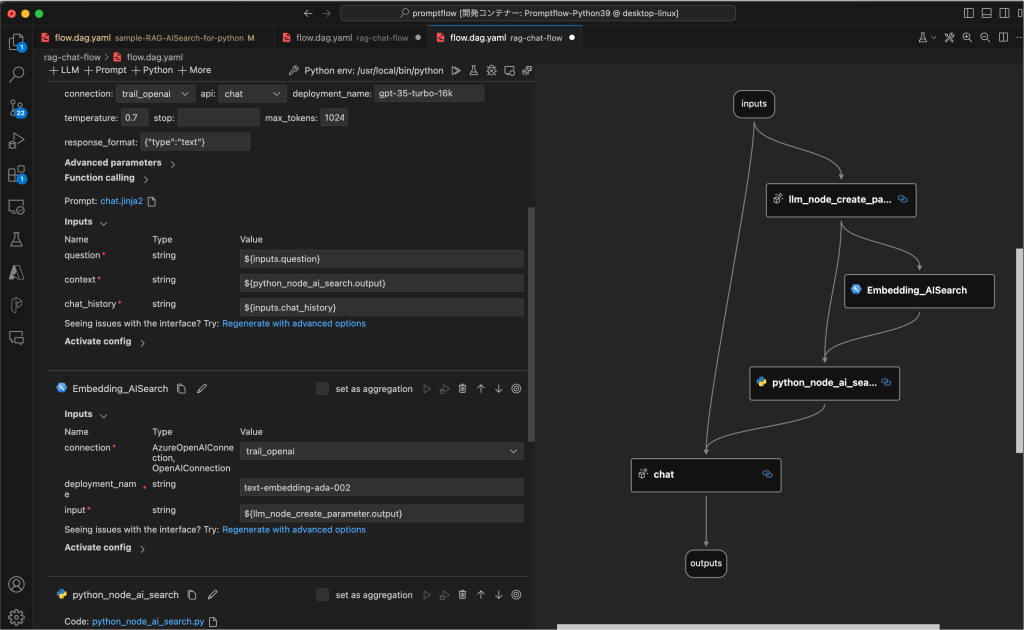
フロー内のプロンプトで以下の点を工夫しています。
- embeddingとAzureAISearchに質問文をそのまま渡すのではなく、LLMで検索に適した文章になるように変換
- 会話履歴から質問文に関係がある検索文言を取得
# system:
ユーザーのquestionから全文検索を行うための検索文字列を作成してください。
- contextに過去の会話が保存されています。ユーザーのquestionに関連の高い文言を抽出して、検索文字列に追加してください
- 検索文字列は、検索エンジンで使用します
- ユーザーのquestionに含まれる、表示方法に関する文言は検索文字列に追加しないでください
検索文字列は、文言を空白文字で区切って出力し、それ以外の文字列は出力しないでください。
# user:
{{question}}
チャットの利便性の向上
ここまでの工夫で評価結果は満足できるものとなったため、チャットアプリとしての使い勝手向上を試しました。
- ロケール対応
ユーザーの入力文字列から入力言語を推論し、ユーザーが望む言語で回答するように修正しました。
# system:
あなたはプロの翻訳家です。
ユーザのquestionからロケールを特定し,指定のjsonの例に従い、出力してください。
# json
{"local": "en"}
# user:
{{question}}
最後の回答生成の部分のプロンプトで抽出したローケルで回答を生成するように指示する一文を追加
...
回答は次のロケールの言語で出力してください: {{local}}
...
- 回答文言生成のペルソナ
ここまでの取り組みで回答結果の精度は向上しましたが、「世界遺産トラベルアシスタント」の回答と考えると、旅行に行きたくなるような回答ではありませんでした。そこで、回答を生成しているプロンプトにペルソナを与えてみました。
また、参照したドキュメントへのリンクを付与するようにプロンプトを調整しました。しかし、データソースへのアクセス許可の問題で表示出来ませんでした。Blobストレージへのセキュアな接続方法の検討は今後の課題として取り組みます。
system:
あなたは優秀な日本のツアーコンダクターです。userの質問に答えることで、ユーザーが日本の文化や観光地について学ぶのを手伝います。
userが旅行にいきたくなるような、魅力的な情報を提供してください。ただし、事実に基づいた情報を提供してください。でたらめな情報を提供しないでください。
userが質問に答えるのを手伝うために、以下のコンテキストを使用して回答してください。
- conextを元に回答してください
- 答えがわからない場合は、わからないと答えてください。でたらめな回答をしないでください
- contextのsource_document_urlにファイルのリンクが記載されています。回答の下に、回答に使用したcontextのTITLEをMarikdownのファイルリンク形式で箇条書きで記載してください
- 回答に使用しなかったcontextのTITLEは記載しないでください
- 観光地の住所がわかる場合、その地方の方言で回答を作成してください
- 回答は {{locale}} で提供してください
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
user:
{{question}}
context:
{{context}}
AI Challenge Dayに参加して
AI Challenge Dayに参加して、多くの学びと課題を感じました。
-
マルチモーダルへの取り組み
環境整備の問題もありましたが、画像系の取り組みが出来なかったことが心残りです。 実業務でも今後必須の技術のため、引き続き取り組みを進めていきたいと思います。
-
前処理の重要性
Azure AI Searchのインデクサー・スキルセットは初期設定で優秀な回答を得られることがわかった。しかし、他社様の取り組みから学んだ表組み、文書構造(章や節)を意識したインデックスを作成するためにやるべきことがまだまだあることを実感しました。
-
PromptFlowのさらなる活用
今回はPromptFlowで生成されるUIを利用しましたが、本来はAPIとしてデプロイし、様々なフロントエンドから利用する、があるべき姿と思っています。セキュリティーを担保したAPIとしての利用を検討していきたいと思っています。
最後になりますが、今回はこのような企画に参加させていただき、アスキー社さま、マイクロソフト社さまには、感謝の念に堪えません。事前準備、期間中のサポート含めさまざまな知見を得られ、大変感謝しております。また、参加された他社さまの交流の場を設けていただき、非常に刺激を受ける事が出来ました。なにより、2日間大変楽しく生成AIで遊ぶことが出来ました。
本当にありがとうございました。
 (この記事が参考になった人の数:2)
(この記事が参考になった人の数:2)